[논문리뷰] Transformer - Attention Is All You Need
이 포스트는 Attention Is All You Need로 유명한 transformer에 대한 포스트입니다. NLP로 처음 transformer를 접했었는데 최근에는 비전 분야에서도 SOTA 기술로 적용되는 등 놀라운 성과를 보여 이번 기회에 transformer에 대해 정리해야겠다는 생각이 들어 본 글을 작성했습니다.
Transformer는 나온지 꽤 됐을 뿐더러, 많은 분야에서 사용되는 기술인만큼 여기저기서 좋은 자료를 찾을 수 있습니다. 저도 상당 수를 참고 자료에 넣어놓은 링크에서 참고했다는 점 먼저 말씀 드립니다.
1. 요약
1-1. Transformer의 특징
- Encoder, Decoder를 발전시킨 모델
- RNN을 사용하지 않음
- 병렬화
→ 순차적인 모델이 아니고 병렬화가 가능하다는 점에서 속도가 빠르다.
1-2. Keyword
Transformer와 관련된 가장 중요한 keyword는 아래와 같습니다. 이 개념들만 제대로 알면 transformer의 상당 부분을 이해했다고 할 수 있습니다.
- Positional Encoding: RNN이 없이도 순서 정보를 나타낼 수 있도록 단어의 위치 정보를 인코딩
- Self-attention (query, key, value): 각 query와 key의 상관 관계를 나타냄 (query: 현재 단어, key: 현재 단어와 상관 관계를 비교할 다른 단어)
- Multi-head attention
2. Key Idea
2-1. Positional Encoding
RNN이 없이도 단어의 순서 정보를 나타낼 수 있도록 단어의 위치 정보를 삼각함수를 이용하여 인코딩 합니다.
\[PE_{(pos,2i)}=sin(\frac{pos}{10000^\frac{2i}{d_{model}}})\\ PE_{(pos,2i+1)}=cos(\frac{pos}{10000^\frac{2i}{d_{model}}})\]- Encoder 및 decoder 입력 값마다 상대적인 위치 정보를 추가해준다.
- Word embedding에 positional embedding을 더한다.
- -1에서 1 사이의 값이 나온다.
2-2. Self-Attention
현재 단어와 다른 단어들 사이의 상관 관계를 구하는 부분입니다. 이 때 현재 단어는 query로 표현되고, 현재 단어와 비교할 다른 단어를 key로 나타냅니다.
- Encoder에 입력된 벡터들(각 단어의 임베딩 벡터)로부터 3개의 벡터(query, key, value)를 만듭니다. Query와 key는 단어 사이의 상관 점수를 구하는 데에 사용됩니다.
- Query: 현재 단어
- Key: 현재 단어와 상관 관계를 비교할 다른 단어
- Value
세 개의 벡터가 만들어지는 방법은 입력 단어 벡터에 대해 세 개의 행렬(Wq, Wk, Wv)을 곱하여 만듭니다. 이 세 개의 행렬은 학습을 통해서 구해야 하는 행렬입니다.
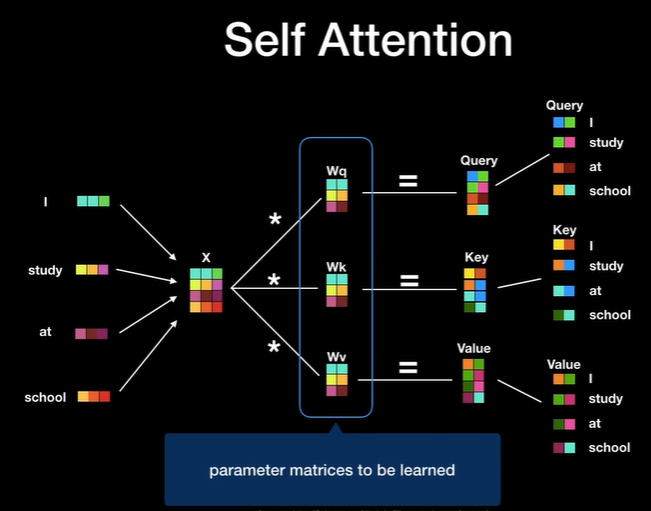 출처: Transforemr 설명 영상
출처: Transforemr 설명 영상- Attention Score: query와 key를 곱한 값입니다. 이 값이 클수록 두 단어 사이의 연관성이 높다는 것을 의미합니다.
Attention Score에 softmax 연산을 취해 확률값으로 변환합니다. 이 때 key의 dimension으로 나눠주는 것은 key의 차원이 커질수록 dot product 결과 값이 증대되는 것을 보완하려함입니다.
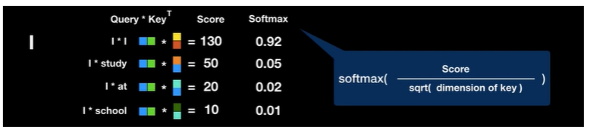 Attention Score에 softmax연산을 취해 확률값으로 변환. I와 I는 0.92의 상관 관계. I와 study는 0.05, I와 at은 0.02, I와 school은 0.01임을 의미한다. 출처: Transforemr 설명 영상
Attention Score에 softmax연산을 취해 확률값으로 변환. I와 I는 0.92의 상관 관계. I와 study는 0.05, I와 at은 0.02, I와 school은 0.01임을 의미한다. 출처: Transforemr 설명 영상Attention score에 softmax를 취해 구한 결과값에 value 매트릭스를 dot product합니다. 이 과정을 통해 연관성이 적은 value는 흐려지게 됩니다.
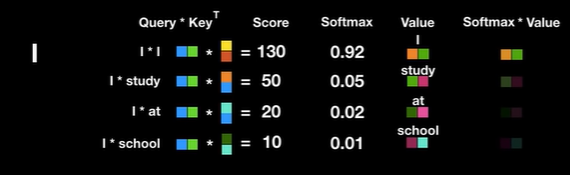
Softmax의 결과값과 value를 곱해진 weighted value vector를 각 query에 대해 합한다. 이 과정을 모든 query에 대해서 하면 전체 문장에서의 query가 지닌 전체적인 의미를 나타내는 벡터로 바뀐다.
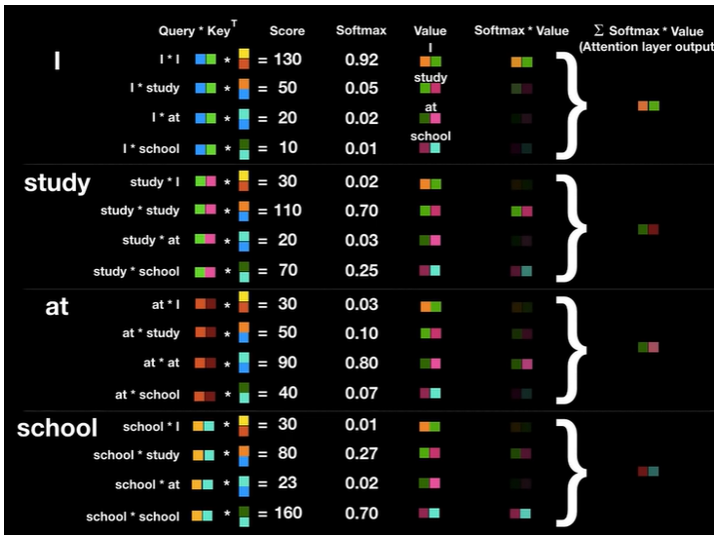
- Self-attention을 하나의 그림으로 나타내면 아래와 같습니다. Query와 key를 dot product한 값을 key의 dimension 정보를 이용하여 노멀라이즈하여 softmax에 넣어 attention score를 구합니다. 그 attention score와 value를 dot product하여 나온 결과를 같은 query에서 나온 값끼리 합쳐 z를 구합니다.
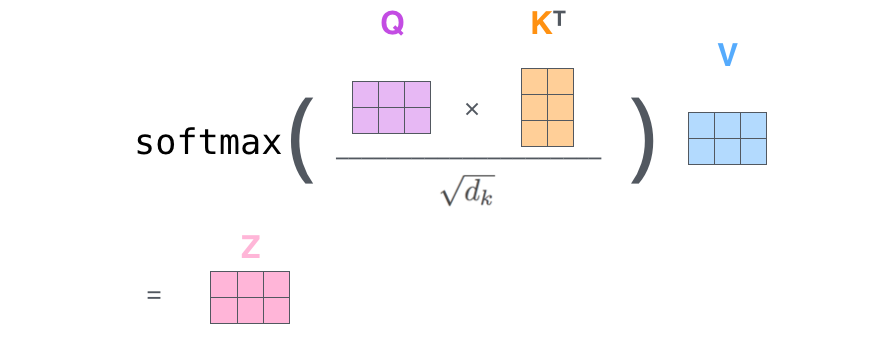 출처: The Illustrated Transformer
출처: The Illustrated Transformer
2-3 Multi-Head Attention
- 여러 개의 attention layer를 동시에 수행하여 성능을 개선합니다. 즉, 각 query에 대해 하나의 결과값이 나오는 것이 아니라 설정한 head 수 만큼의 결과값이 나옵니다. (Query, key, value 매트릭스의 수도 그만큼 증가합니다.)
- 하나의 attention으로는 모호한 문장을 충분히 표현하기 어렵기에 사용합니다.
- 동일한 문장을 여러 명이서 본 후에 각각의 관점을 합하는 것과 같은 효과를 지닙니다.
Head수 만큼 나온 결과를 연결한 후, weight matrix와 곱한 후 Fully connected layer(FC)에 보냅니다.
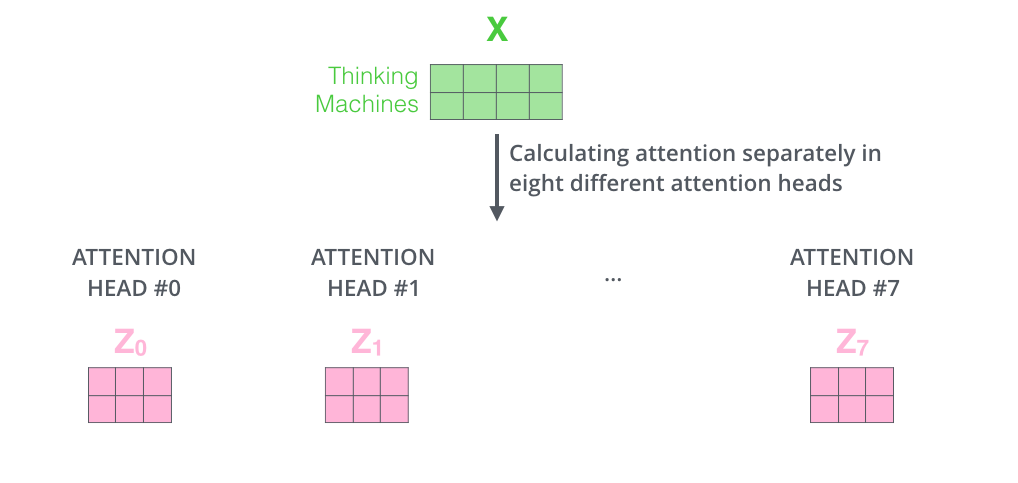
Head수를 8로 설정한 경우에는 입력 값에 대해 8개의 attnetion layer 결과값이 나오게 됩니다.
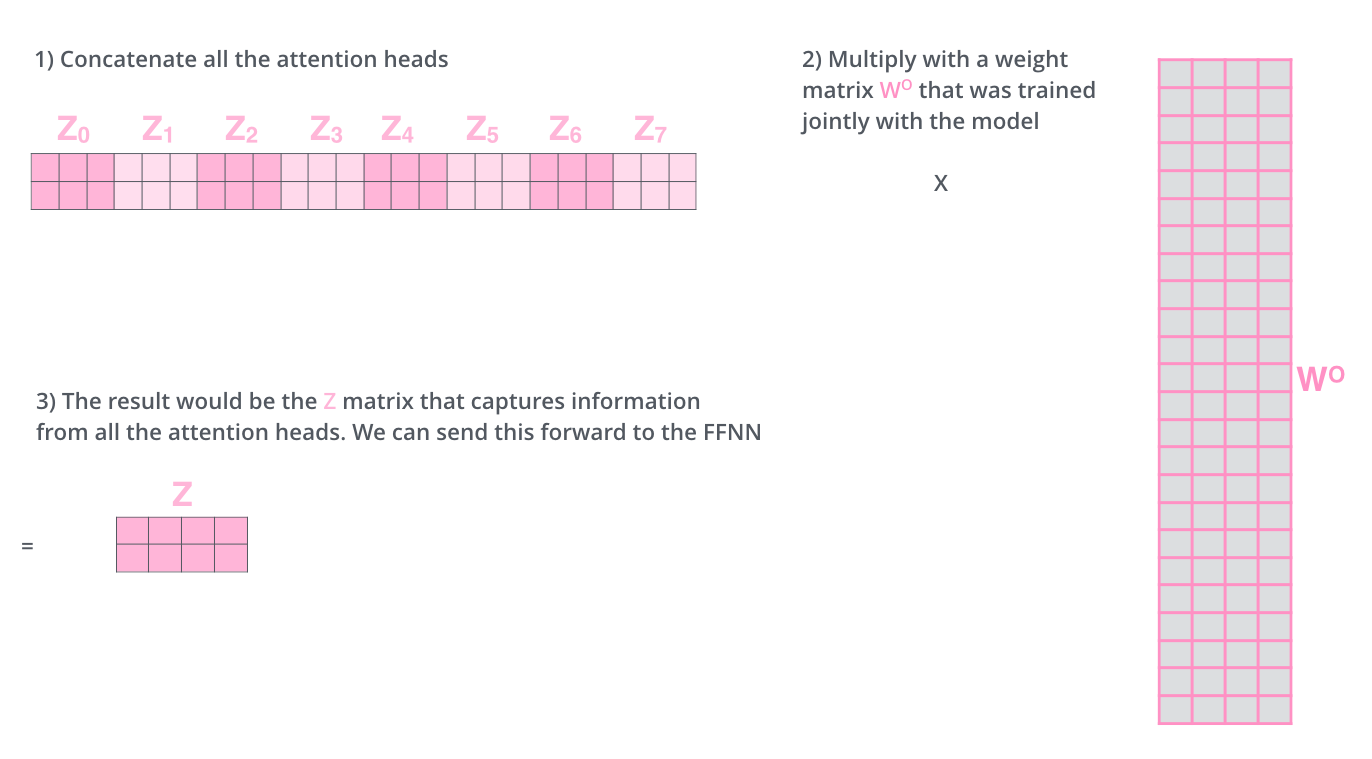
3. Transformer
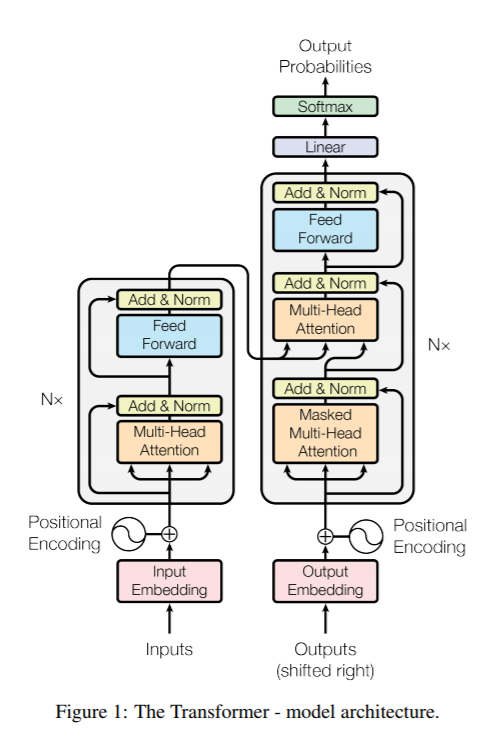
위 그림은 전체적인 transformer의 구조입니다. 크게 Encoder와 Decoder로 구성된 것을 확인할 수 있습니다.
3-1. Encoder
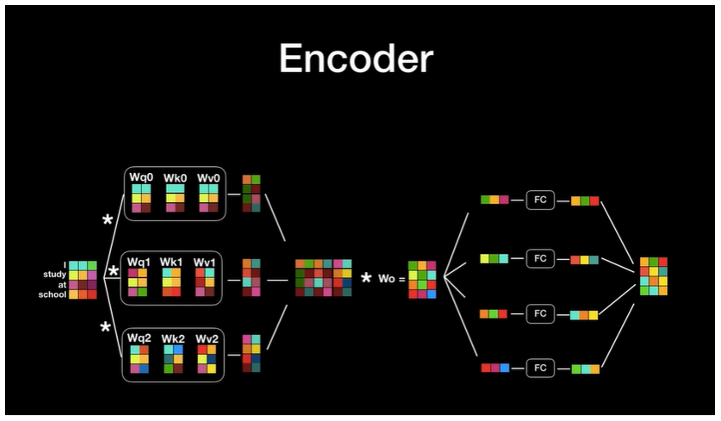
Encoder에서 일어나는 동작은 아래와 같습니다.
- 단어를 워드 임베딩으로 전환합니다.
- Positional Encoding을 통해 단어의 순서 정보를 더합니다.
- Query, Key, Value를 이용한 multi-head attention의 결과값이 나옵니다.
- 그 결과값이 각각 FC에 들어갑니다.
Back-propagation에 의한 정보 손실을 방지하기 위해 residual 개념을 추가합니다.
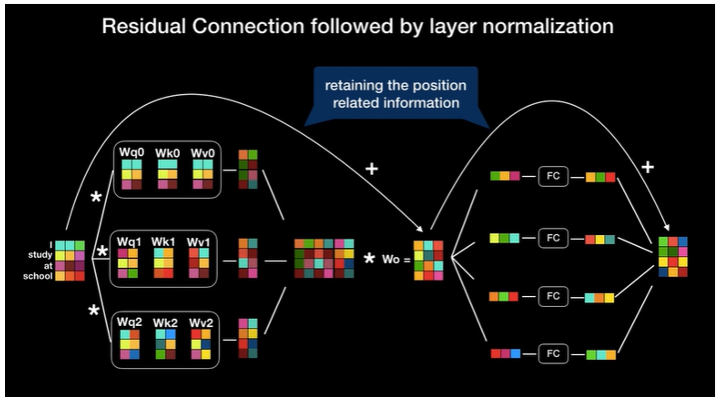
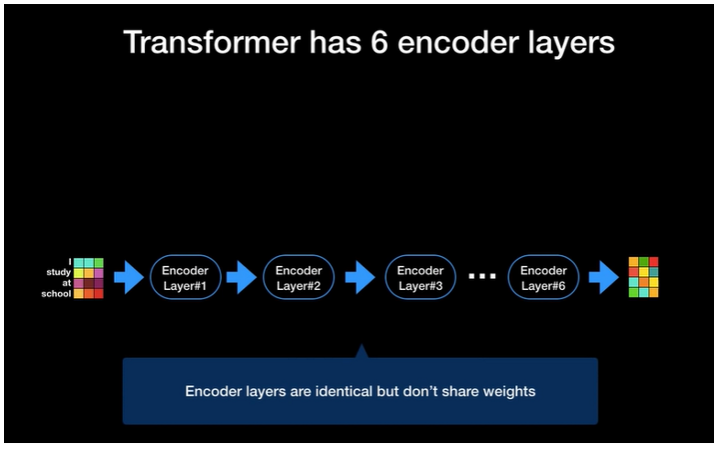
- 인코더의 출력 벡터의 크기가 입력 벡터와 같으므로, 인코더를 여러 개 붙여서 사용할 수 있습니다.
Transformer는 총 6개의 인코더 레이어로 이루어집니다.
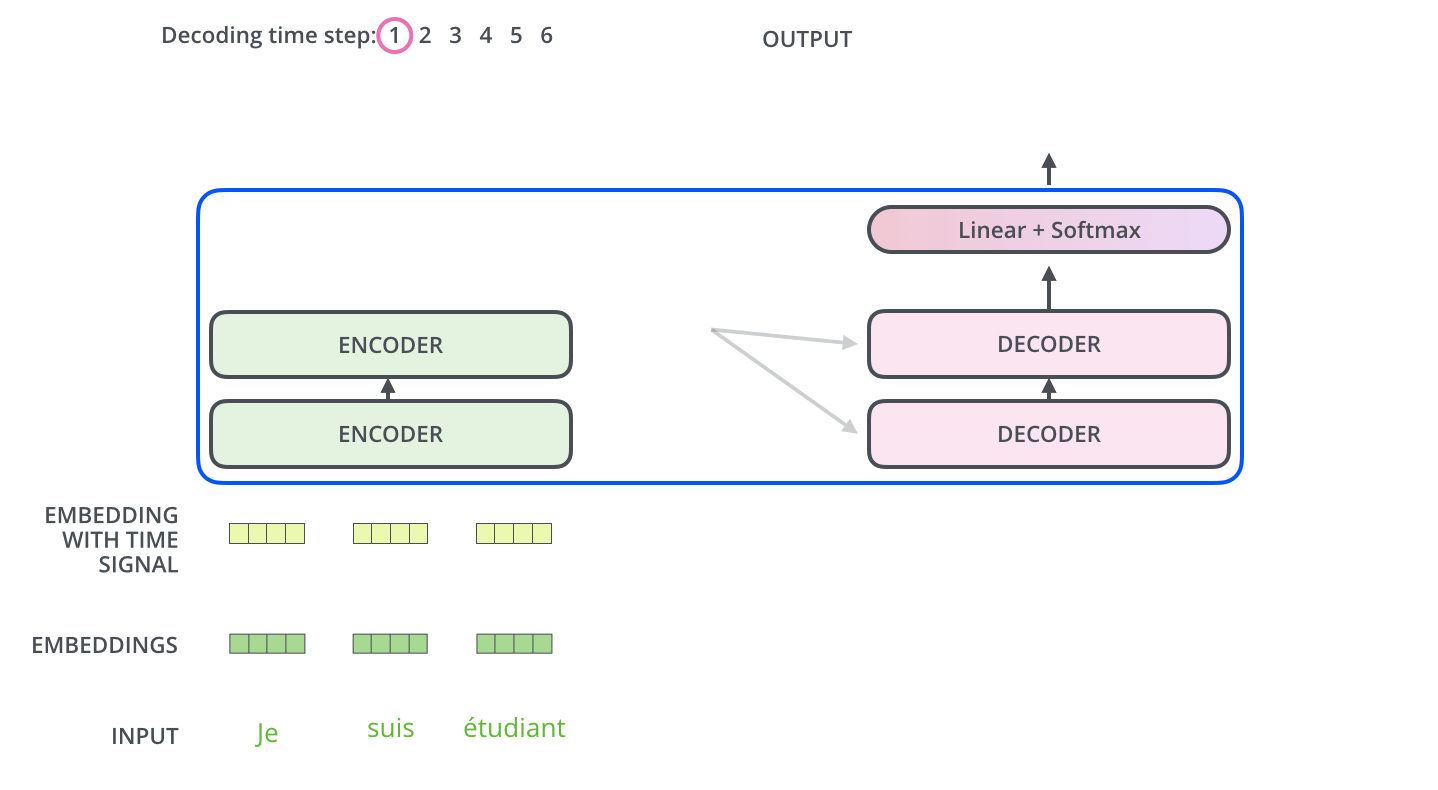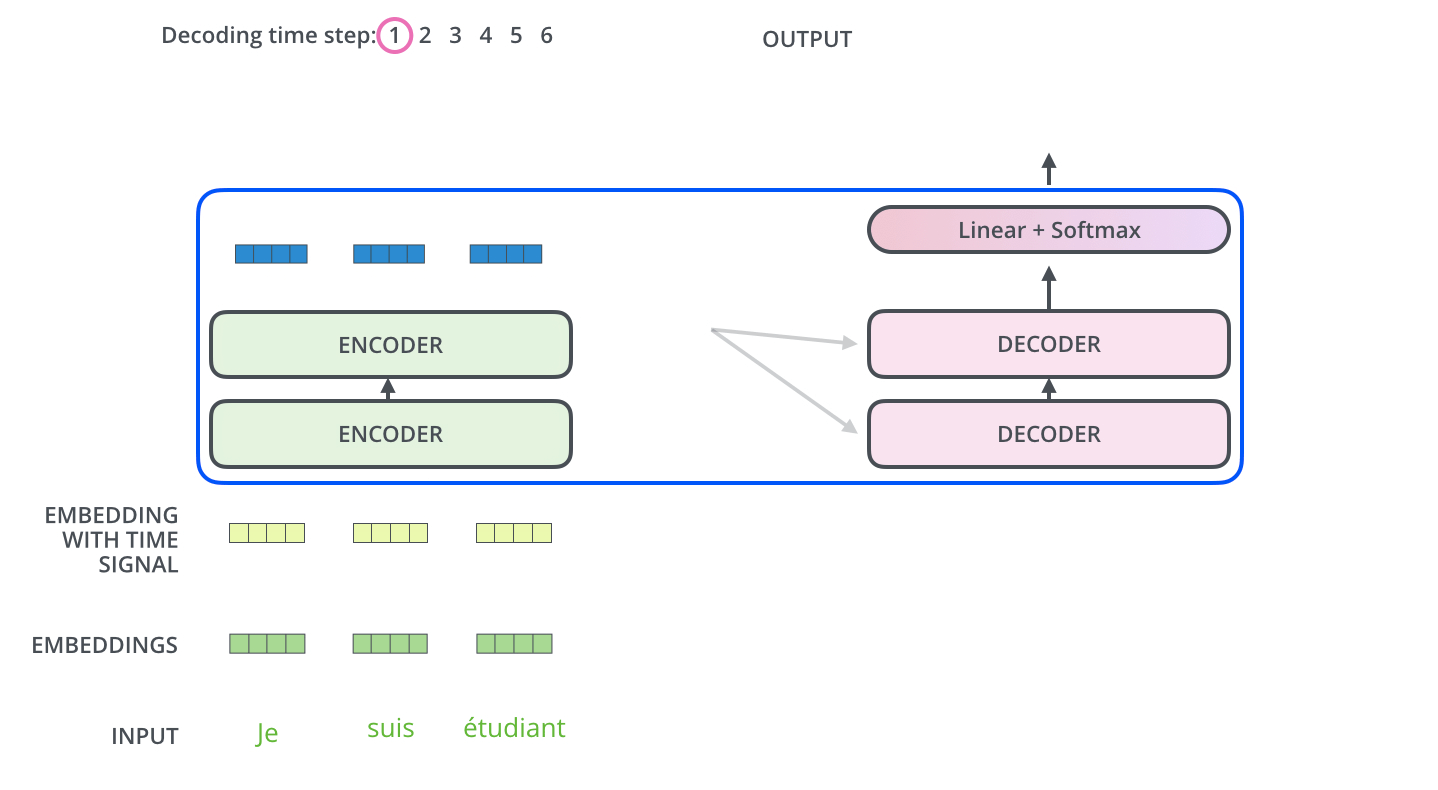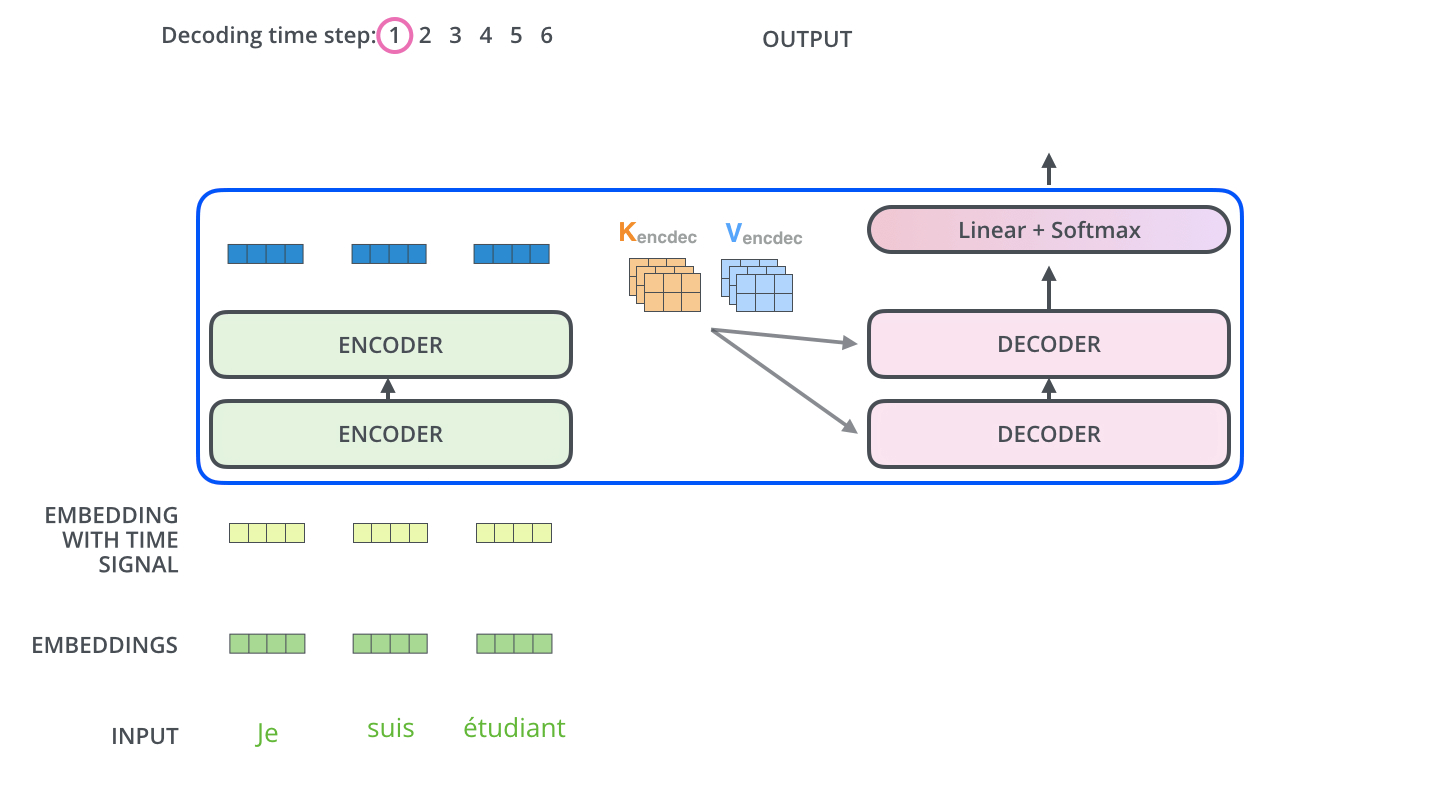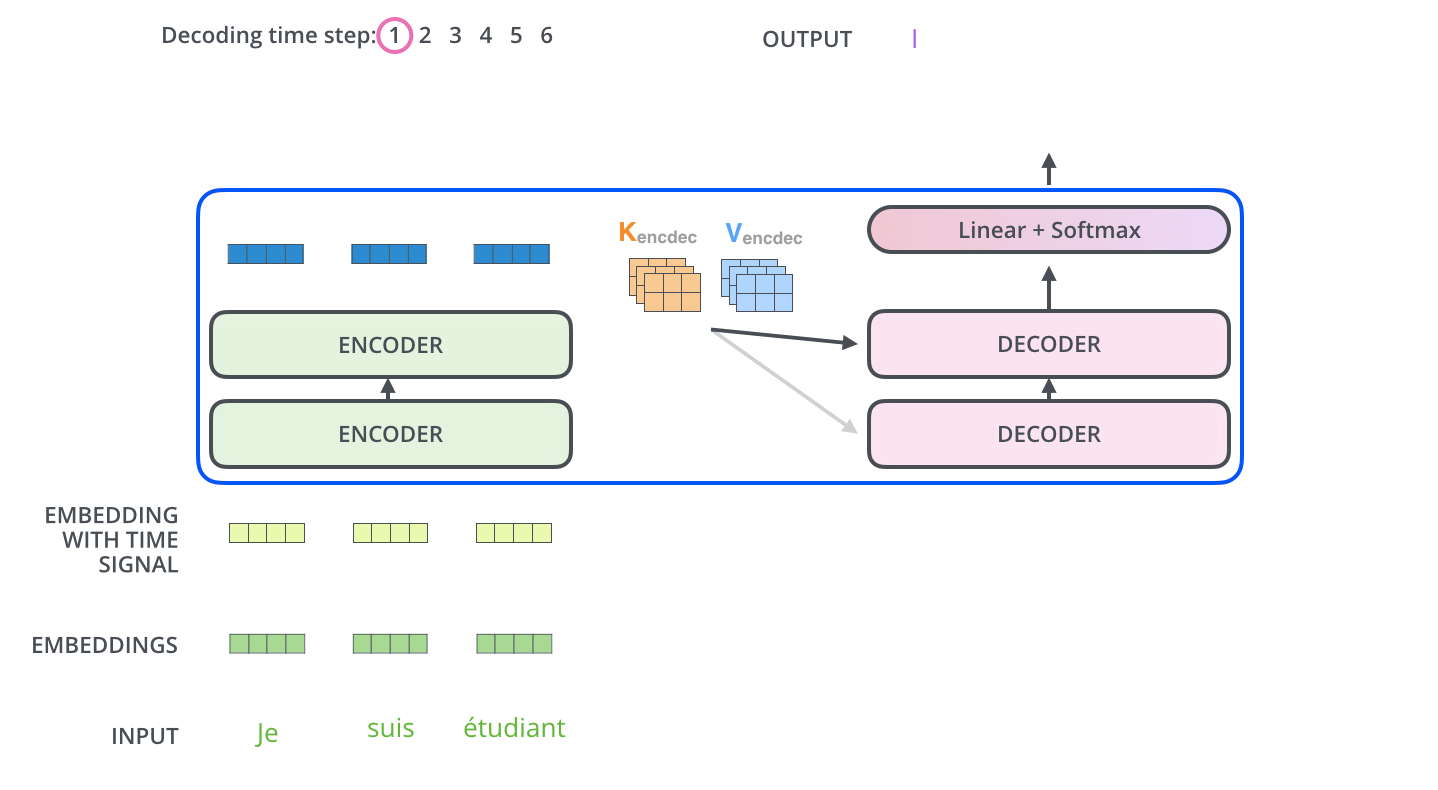
3-2. Decoder
- 디코더에는 인코더에는 나오지 않는 masked multi head attention 개념이 등장합니다. 이것이 필요한 이유는 아직 나오지 않은 미래의 단어에 attention을 하면 안되므로, 그런 단어에 대해서 마스크를 취하는 것입니다.
- Query는 이전 디코더 레이어의 값을 사용하고, key와 value는 인코더의 값을 사용합니다.
코드를 보면 더 이해가 명확하게 될 것입니다. 본 글을 보고 애매한 부분이 있으시다면 이 글을 통해 코드랑 같이 보시는 것을 추천합니다.