[논문리뷰] Weakly Supervised Lesion Localization With Probabilistic-CAM Pooling
1. 요약
본 논문에서 저자들은 기존의 pooling 기법과 차별은 둔 Probabilistic Class Activation Map (PCAM) pooling을 제안하였다. PCAM pooling은 트레이닝 하는 동안 CAM의 우수한 localization 능력을 활용한다. 이 방법을 chestX-ray 데이터셋에 적용한 결과 classification과 localization 측면에서 모두 SOTA를 달성하였으며, heatmap도 좀 더 확실하게 생성할 수 있었다.
2. Contribution
- Post-processing 기술 정도로만 사용하던 CAM (Class Activation Map)을 트레이닝 과정에 사용하여 classification과 localization 성능을 높였다.
3. Global pooling
Global average pooling 기법은 이미지 분류 분야에서 널리 쓰이고 있다. Global average pooling을 이용해 네트워크 오버피팅을 방지할 수 있지만, chest CAD 분야에서는 뚜렷한 병증을 highlight하는 능력이 떨어질 수 있다는 약점이 있다. 이를 보완하기 위해 아래와 같은 다양한 global pooling 기법들이 제안되었다.

$C$: channel dimension, $H$: Height of the feature map, $W$: Width of the feature map $X_{c,i,j}$: feature map
4. Probabilistic-CAM (PCAM) pooling
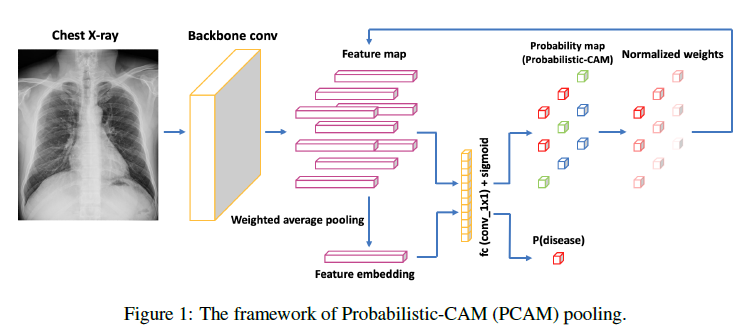
Backbone (논문에서는 ResNet-34) 이 되는 마지막 convolution layer[1]로부터 나온 feature를 feature map $X_{i,j}$ 라 한다. 그 feature map은 1x1 convolution layer로 이루어진 fc (fully connected) layer를 거치게 된다. 이 fc 레이어는 backbone의 마지막 convolution layer와 같은 채널 수를 입력 채널로 출력 채널은 1을 가지는 레이어다. fc 레이어를 거쳐서 나온 값은 logit $s_{i,j}$라 한다.(shape: [batch_size, 1, H, W]의 dimension을 가짐) 이 logit $s_{i,j}$는 추후 노멀라이징 하여 heatmap으로 사용된다.
한편, 이 논문에서 특이점은 heatmap을 생성하는 logit을 학습 중에 이용하여 localization을 가이드하고 binary classification하는 데에 사용한다는 것이다. 이 과정은 아래의 식을 이용하여 pooled feature embedding $x$를 만드는 것으로 시작된다.
\[x = \varSigma_{i,j}^{H,W}w_{i,j}X_{i,j}\] \[w_{i,j} = \cfrac{\text{sigmoid}(w^TX_{i,j}+b)}{\varSigma_{i,j}^{H,W}\text{sigmoid}(w^TX_{i,j}+b)}\]$w_{i,j}$는 $X_{i,j}$의 attention weight를 의미한다. 이것은 fc layer를 지나 얻어진 logit을 sigmoid하여 값을 bound한 다음에 노멀라이징한 값이다. pooled feature map $x$는 이 attention weight와 backbone의 마지막 레이어에서 나온 $X_{i,j}$를 곱하여 height와 width 축에 대해 모두 더한 값이 된다. 이 pooled feature map $x$가 다시 fc layer를 지나 최종적으로 질병에 대한 확률값이 나온다.
사실 논문보다는 저자가 공개한 소스코드를 보는 것이 더욱 이해가 빠르다(https://github.com/jfhealthcare/Chexpert). 아래가 모델의 forward 과정 중에 일어나는 부분이다. 코드의 간결함을 위해 불필요한 부분은 삭제하였다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
def forward(self, x):
# (N, C, H, W)
feat_map = self.backbone(x)
# [(N, 1), (N,1),...]
logits = list()
# [(N, H, W), (N, H, W),...]
logit_maps = list()
for index, num_class in enumerate(self.cfg.num_classes):
classifier = getattr(self, "fc_" + str(index))
# (N, 1, H, W)
logit_map = classifier(feat_map)
logit_maps.append(logit_map.squeeze())
# (N, C, 1, 1)
feat = self.global_pool(feat_map, logit_map)
if self.cfg.fc_bn:
bn = getattr(self, "bn_" + str(index))
feat = bn(feat)
feat = F.dropout(feat, p=self.cfg.fc_drop, training=self.training)
# (N, num_class, 1, 1)
logit = classifier(feat)
# (N, num_class)
logit = logit.squeeze(-1).squeeze(-1)
logits.append(logit)
return (logits, logit_maps)
먼저 입력 x를 backbone에 넣어 feat_map (shape: [batch_size, C, H, W])을 얻는다. 그리고 fc layer를 의미하는 classifier의 feat_map을 넣어 logit_map(shape: [batch_size, 1, H, W])을 얻는다. 이 logit_map의 channel dimension을 squeeze()로 축소하여 heatmap을 만드는 값으로 사용한다.
Heatmap: backbone의 출력 x 가 1x1 fully convolutional layer에 들어간 결과물
feat_map과 logit_map을 이용해서 global_pooling을 한다. 이에 대한 함수는 아래와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class PcamPool(nn.Module):
def __init__(self):
super(PcamPool, self).__init__()
def forward(self, feat_map, logit_map):
assert logit_map is not None
prob_map = torch.sigmoid(logit_map)
weight_map = prob_map / prob_map.sum(dim=2, keepdim=True)\
.sum(dim=3, keepdim=True)
feat = (feat_map * weight_map).sum(dim=2, keepdim=True)\
.sum(dim=3, keepdim=True)
return feat
logit_map에 sigmoid를 취해서 prob_map을 만들고 attention weight인 weight_map (shape: [batch_size, 1, H, W]을 구한다. weight_map과 feat_map을 곱한 것을 W와 H 축에 대해 sum을 취해 feat(shape: [batch_size, C, 1, 1]) 를 만든다.
최종적으로 이 feat가 classifier에 다시 들어가 병증에 대한 positive 확률을 나타내는 logits이 된다.
정리해보자면, fc layer를 거쳐서 나온 logit_map은 heatmap을 만드는 데에 사용되고, 이 logit_map을 이용해 weight map을 만든 후 backbone의 마지막 레이어 값과 곱해져 병증에 대한 확률 값이 된다.
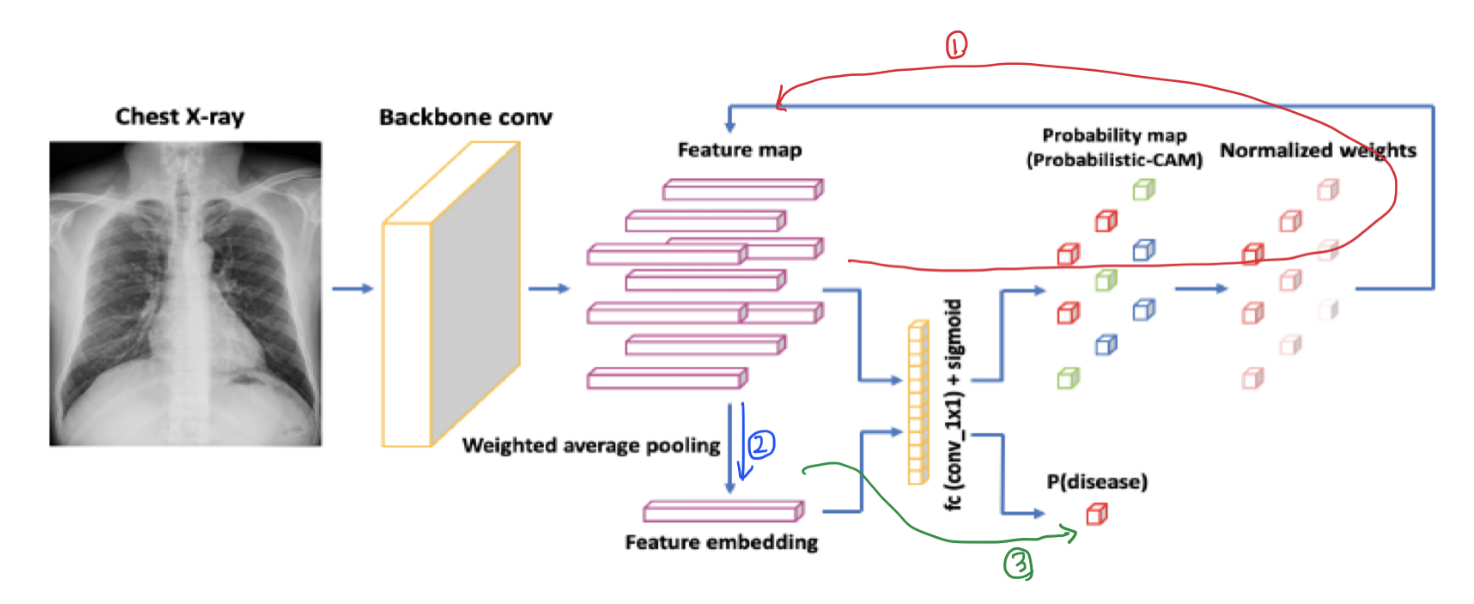
즉, 위의 그림을 다시 순서대로 나타내면 다음과 같다.
① Backbone의 출력물인 feature map을 classifier에 넣어 logit map을 만든다. Feature map과 logit map을 가지고 attention weight를 만든다.
② 만들어진 attention weight를 feature map과 곱해 feature embedding을 만든다.
③ feature embedding을 fc layer에 넣어 병증에 대한 확률값을 얻는다.
5. 실험 결과
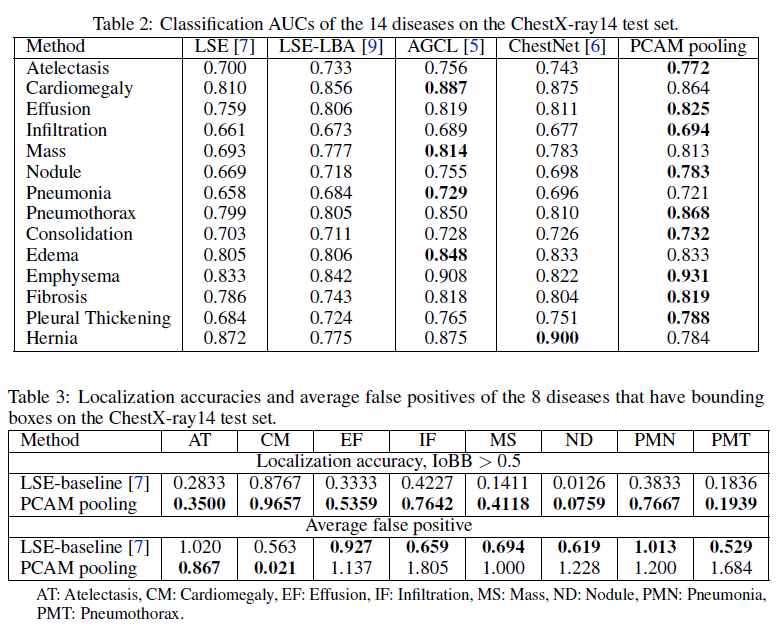
PCAM pooling을 이용한 방법이 classification이나 localization에서 좋은 성능을 보였다는 결과이다.
6. 추가 사항
PCAM pooling을 이용할 경우 병변에 대해 heatmap을 더 크게 생성하는 경향이 있다. 이로 인해 작은 병변에 대한 false positive가 증가할 수 있다고 한다. 한편, github에 올라와있는 모델은 현재 cheXpert 데이터셋의 대해 2번째로 좋은 기록을 가지고 있는 모델이다.(https://stanfordmlgroup.github.io/competitions/chexpert/)
네트워크 전체 구조는 공통의 backbone + N classifier (N: 병변의 개수) 형태로 이루어져 있다.