[논문리뷰] Lumiere: A Space-Time Diffusion Model for Video Generation
안녕하세요. 오늘은 구글리서치 그룹에서 발표한 Lumiere에 대해 소개 드리려고 합니다. 다만 아쉽게도 Imagen부터 해서 구글은 공식적인 코드를 공개하고 있지 않습니다. 또한 Make-a-Video 논문에서처럼 해당 논문에서도 구체적으로 언급하고 있지 않은 내용들이 많은데요. 아마 해당 분야 경쟁이 심화 되면서 구글 측에서는 모든 정보를 공개하지 않기로 방향을 정한 게 아닌가 싶습니다.
따라서 공식 코드를 올라오지 않을 것 같지만 lucidrains님께서 해당 레파지토리를 만든 것으로 보아 곧 해당 코드를 구현해서 업로드하실 것 같습니다.
본 글의 내용은 Lumiere 논문 구성과 동일한 구성으로 작성했으며, Lumiere가 실제로 만든 동영상은 해당 페이지를 통해 확인해보실 수 있습니다.
💡 핵심 요약
- 기존 text-to-video 모델들이 시간 안에서 일관성 있는 비디오를 만들지 못한다는 문제를 해결하였다.
- 기존 방법에서는 서로 떨어진 key frame에 대해 비디오를 생성하고 그 사이를 보간법을 통해 채웠다.
- 하지만 이 방법은 일관성 있는 비디오를 얻기 어렵다는 한계점이 있었다.
- 해당 문제를 해결하기 위해 비디오를 전체 시간에 대해 한 번에 생성할 수 있는 새로운 U-net 구조를 제안한다.
- 베이스 모델로는 사전 학습된 텍스트-이미지 디퓨전 모델인 Imagen을 활용하였다.
- text-to-video에 대해서 SOTA를 달성하고, 다양한 분야에서 활용될 수 있음을 보여주었다.

1. Introduction
현재 Text-to-image 기술은 상용화가 가능할 정도로 많이 발전한 상태지만, Text-to-video 분야는 아직 해결해야 할 과제가 많습니다. 그 어려움으로는 아래가 있습니다.
- 자연스러운 동작을 모델링하기 어렵다.
- 메모리와 컴퓨팅 요구사항이 크다.
- 복잡한 분포를 학습하기 위해 필요한 학습 데이터의 규모도 크다.
위 어려움으로 T2V에서는 비디오 길이, 시각적 품질, 사실적인 움직임 표현 등에 제한을 받고 있습니다.
위 문제를 해결하기 위한 T2V 기존 접근 방식은 다음과 같습니다.
- 기존 T2V 접근 방식
- 연속적이지 않은 keyframe을 생성하고 temporal super resolution 모델을 이용하여 그 사이에 누락된 데이터를 생성한다.
- 메모리 면에서는 효율적이지만 일관적인 모션을 생성하는 면에서는 제한이 있다.
이전에 소개 드렸던 Make-a-Video도 다음과 같은 방식을 사용한다고 보면 될 것 같습니다.
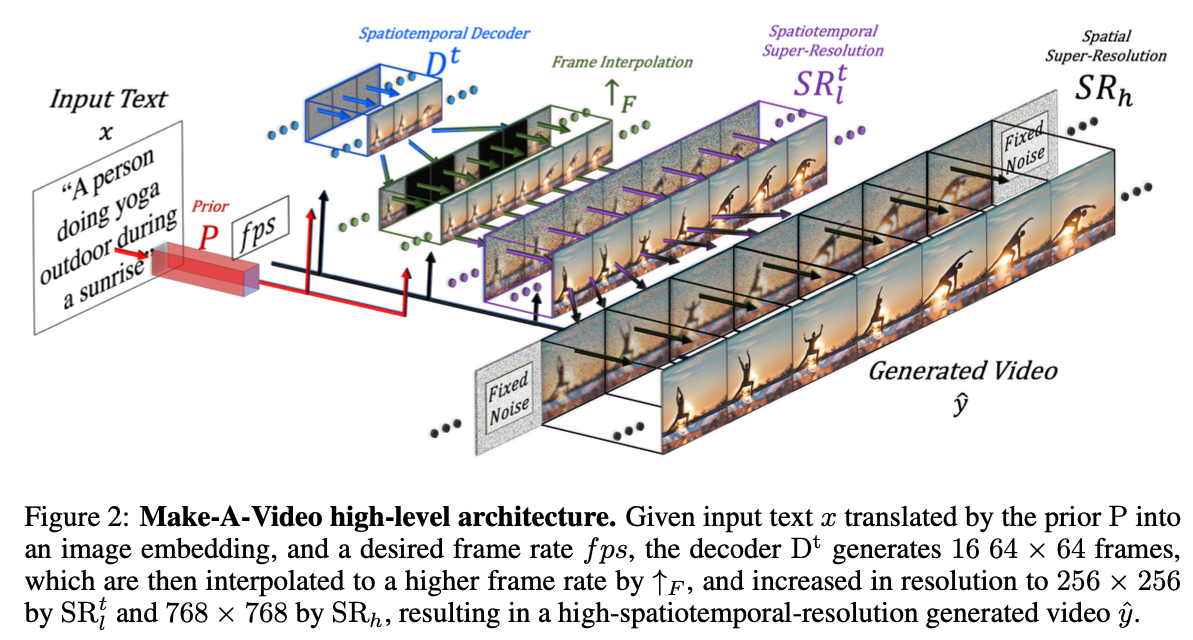 Make-a-Video 구조
Make-a-Video 구조
위와 같이 특정 freame에 대해서만 영상을 만들어내고 그 사이는 frame interpolation을 통해 채우는 것이 기존 T2V 접근 방식이었습니다. 하지만 본 논문에서는 이와 같은 방법은 일관적인 모션을 생성하는 면에서는 제한이 있다고 합니다. 따라서 아래의 방법으로 접근하여 해당 문제를 해결하려고 합니다.
- 본 논문의 접근 방식
- STUNet(Space-Time U-net)을 사용하여 비디오의 전체 시간 길이를 한 번에 생성한다.
- T2I 모델을 pre-trained 모델로 활용하였다.
- 사전학습된 T2I 모델을 기반으로 Lumiere 모델을 구축하였다.
다른 기존 접근 방식과 유사하게 T2I 모델을 베이스 모델로 활용하여서 T2I 모델이 갖는 장점은 그대로 가져왔습니다. 다만 기존 방식과의 차이점은 비디오 전체 시간 길이에 대해 한 번에 생성할 수 있는 구조로 UNet구조를 변경하였습니다. 이를 위해 공간(space)과 시간(time) 신호를 다운 샘플링하여 학습하였고, 대부분의 미디어에서 기존 방법들보다 더 긴 프레임을 생성할 수 있다고 합니다. (16fps에서 80프레임 혹은 5초 이상 영상)
다시 한 번 기존 접근 방식과 논문에서 제안하는 접근 방식의 차이점을 그림으로 나타내면 아래와 같습니다.
- 기존 접근 방식
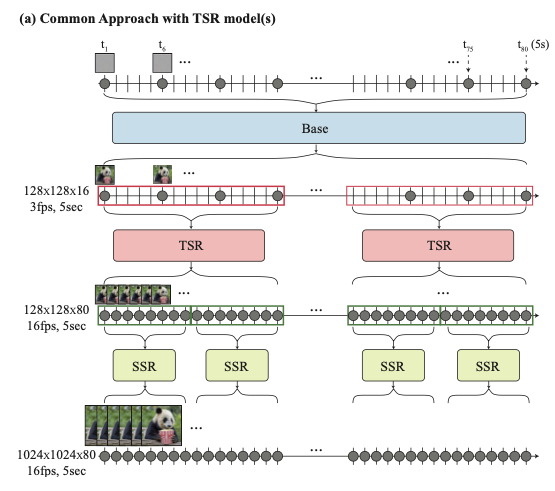
- 베이스 모델로부터 특정 프레임에 대해서만 비디오를 생성한다.
- TSR(Temporal Super Resolution)모델을 통해 보간하여 프레임을 채운다.
- SSR(Spatial Super Resolution)모델을 통해 해상도를 증가 시킨다.
- 본 논문의 접근 방식
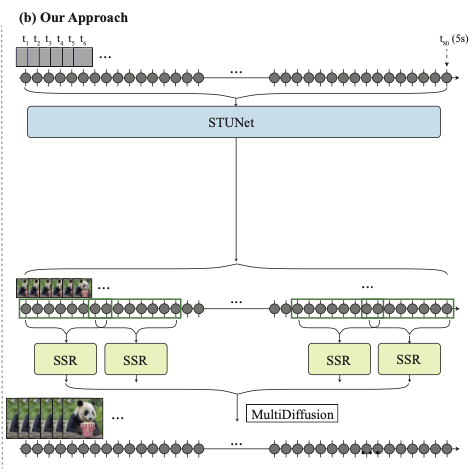
- 모든 프레임에 대해 비디오를 생성한다.
- SSR모델을 통해 해상도를 증가 시킨다.
- MultiDiffusion 방법을 통해 각 프레임이 겹치는 영역을 처리한다.
2. Related Work
기존 관련된 내용으로는 다음가 같습니다.
- Autoregressive Transformer를 이용하거나 Diffusion 모델을 이용한 T2V가 제안되고 있다.
- T2V에 대한 대표적인 접근 방식
- 사전 학습된 T2I 모델에 temporal layer를 추가하고, 추가된 temporal layer만 파인튜닝하거나 전체 모델을 파인튜닝하여 T2I 모델을 T2V 모델로 확장(inflate)한다.
- VideoLDM, AnimateDiff, inflate Stable Diffusion 같은 경우는 추가된 temporal layer만 학습
- 기존 인플레이션 방식은 고정된 시간 해상도를 유지하는 것이 일반적이어서 전체 클립을 처리하는 데는 한계가 있다
- 본 논문에서의 접근 방식
- 공간과 시간 모두에서 비디오를 다운샘플링하는 방법을 학습하고 압축된 네트워크의 시공간 feature space에서 대부분의 동작을 수행하는 새로운 인프레이션 체계를 제안한다.
- Imagen T2I를 확장하였지만, latent diffusion에서도 잘 동작할 수 있고 다른 성능 향상법에도 사용될 수 있다. (diffusion noise scheduler, video data curation)
3. Lumiere
이제 해당 논문에서 제안한 Lumiere에 대해 본격적으로 설명하겠습니다. 위의 기존 접근 방식과의 차이점을 설명한 그림과 같이 Lumiere는 모든 프레임에 대해 비디오를 생성하고, SSR 모델을 통해 해상도를 증가 시킵니다. 또한 MultiDiffusion 방법을 통해 각 프레임이 겹치는 영역을 처리합니다. SSR 모델은 기존 방법에서도 사용되는 모델이니 설명을 생략하겠습니다. 모든 프레임에 대해 비디오를 생성하는 것을 가능하게 해준 논문에서 제안한 Space-Time U-Net(STUnet)과 MultiDiffusion에 대해 설명 드리겠습니다.
3-1. Space-Time U-Net(STUnet)
해당 모델은 모든 프레임에 대해 비디오를 생성하는 모델로, 입력 신호를 공간적인 측면과 시간적인 측면에 대해서 다운 샘플링하여 작업을 수행하는 모델입니다. 베이스 모델로는 T2I 모델 중에 구글이 발표한 Imagen을 사용하였고 여기에 시간적인 정보를 처리할 블록과 모듈을 추가하였습니다.
전체적인 구조는 아래와 같습니다.
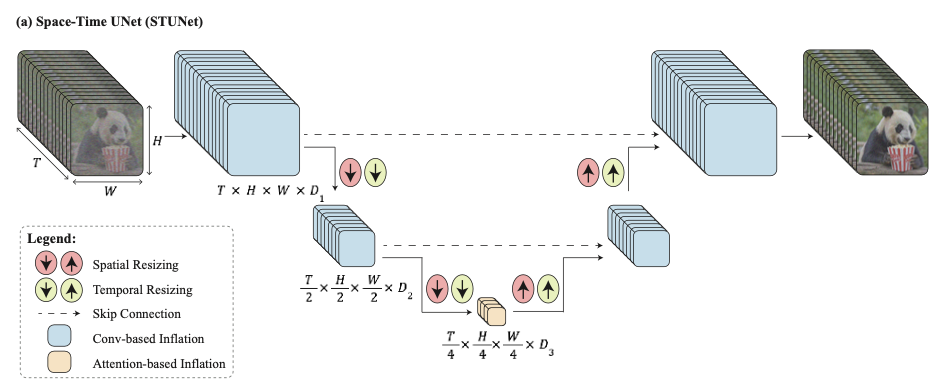
T2I 구조에 temporal block을 넣고, 사전학습된 각 resizing module 뒤에 시간축에 대한 다운/업샘플링 모듈을 추가하였습니다. 기존 UNet과의 차이점은 시간축에 대해서도 다운/업샘플링이 일어난다는 점이 있겠습니다.
여기서 Temporal block으로는 ‘temporal convolution’과 ‘temporal attention’이 있습니다.
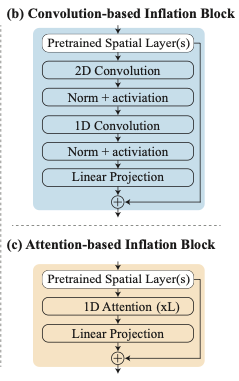
Temporal Convolution은 2D 컨벌루션 결과 이후 1D 컨벌루션을 적용한 결과로 Make-a-Video의 PseudoConv3d와 유사한 구조인 것으로 추측 됩니다. 해당 블록은 가장 coarse한 레벨을 제외한 모든 레벨에 대해 사용 됩니다. 이는 전체 3D 컨벌루션 대비 네트워크의 비선형성을 증가시키면서 계산 비용을 줄이면서, 1D 컨벌루션 대비 표현력을 높일 수 있습니다.
참고로 Make-a-Video의 PseudoConv3d 구조는 아래와 같습니다. 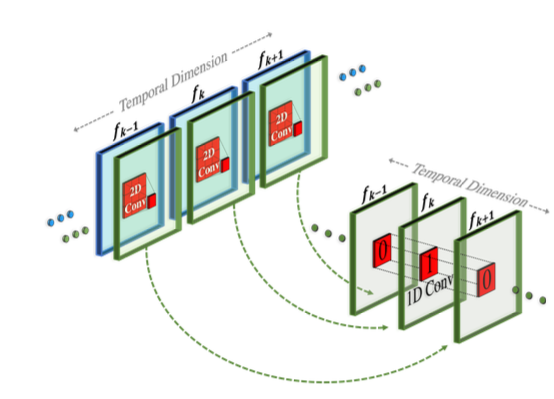
Temporal attention은 사전에 학습된 spatial layer를 기반으로 1D attention을 적용한 결과입니다. 이 블록은 계산량이 크기 때문에 가장 coarse한 해상도에서만 사용 되었습니다.
다른 T2V 방식들과 유사하게 사전훈련된 T2I의 가중치는 고정하고, 새로 추가된 파라미터만 훈련하였습니다.
3-2. Multidiffusion for Spatial-Super Resolution
메모리 제약으로 인해 해상도를 높이는 SSR 네트워크는 비디오의 짧은 세그먼트에서만 작동할 수 있다. 따라서 SSR 네트워크는 모든 프레임을 입력으로 넣을 수는 없고 짧은 세그먼트를 입력으로 넣어줘야 합니다. 그리고 그 출력을 다시 시간 축에 대해서 합쳐주는 작업이 필요합니다. 이 때 세그먼트 간의 바운더리에서 의도치 않은 아티팩트가 발생할 수 있습니다. 이 아티팩트를 피하기 위해 적용한 방법이 Mulidiffusion이라고 이해하시면 될 것 같습니다.
Multidiffusion은 다음의 과정으로 이루어집니다. 먼저, Noisy 입력 비디오를 서로 겹치는 segment로 나눕니다. 즉 아래의 수식으로 표현 될 수 있습니다.
$J\in\Reals^{H\times W\times T \times 3}$ → ${J_i}_{i=1}^N$, where $J_i\in\Reals^{H\times W\times T’ \times 3}$ ($T’<T$)
그리고 세그먼트별 SSR 예측 결과인 {$\Phi(J_i)$}을 조정하기 위해, denoising step의 결과를 아래의 최적화 문제의 해로 정의합니다.
\[\argmin_{J'}\sum_{i=1}^n||J'-\Phi(J_i)||^2\]즉, 겹치는 윈도우에 대한 예측을 선형으로 결합하는 것을 찾도록 합니다.
논문에서는 Multidiffusion에 대해서 이렇게만 소개하고 있어서 자세한 이해는 선행 논문을 읽어야 좀 더 이해가 될 것 같습니다. 이는 추후에 추가하겠습니다.
4. Applications
이 부분에서는 제안한 모델을 어떤 식으로 각 다운스트림 어플리케이션으로 확장할 수 있는지를 보여줍니다. 먼저, 기본 방법과는 달리리 TSR 모듈을 없앤 결과 다운스트림 애플리케이션으로 더 쉽게 확장할 수 있었다고 합니다. 또한, SDEdit을 사용하여 다운스트림 애플리케이션을 직관적인 인터페이스로 이용할 수 있다고 합니다.
4-1. Stylized Generation
원하는 스타일의 비디오를 생성하기 위해서 이전의 방식들은 사전 학습된 T2I weight를 원하는 스타일의 비디오를 생성할 수 있도록 커스텀된 모델로 대체하곤 했습니다. 하지만 이런 간단한 ‘plug-and-ply’방식은 종종 왜곡되거나 정적인 비디오를 생성하곤 하였다고 합니다. 이는 파인 튜닝된 공간 레이어에서 시간 레이어로의 입력 분포가 크게 벗어나기 때문이라고 본 논문에서는 추측하였습니다.
따라서 해당 논문에서는 GAN 기반 보간 방법에 영감을 받아 파인 튜닝된 T2I 가중치($W_{style}$)와 원래 T2I 가중치($W_{org}$)를 선형 보간하여 스타일과 모션 사이의 균형을 맞추는 방법을 선택하였습니다.
- 보간가중치
- $W_{interpolate}=\alpha\cdot W_{style} + (1-\alpha)\cdot W_{org}$
- $\alpha\in[0.5, 1]$ → 실험을 통해 수동으로 선택
이를 적용한 Stylized Generation 결과는 아래와 같습니다.

수채화 같이 보다 사실적인 스타일은 사실적인 모션을 생성하였으며, 벡터 아트 스타일에서 파생된 것은 독특하고 비현실적인 모션을 생성하였다고 합니다.
4-2. Conditional Generation
해당 모델은 추가적인 입력 신호(이미지나 마스크)를 넣어서 조건에 따라 비디오 생성을 할 수 있는 모델로 확장할 수 있다고 합니다. 이를 위해 Noisy video $J$ (3채널), masked conditioning video $C$ (3채널), 바이너리 마스크 $M$(1채널)을 연결하여 7채널 짜리 입력을 만듭니다.
즉, $<J,C,M>\in\Reals^{T \times H \times W \times 7}$가 됩니다. 이를 위해 첫번째 컨벌루션 레이어의 채널 축을 3에서 7로 확장하였고, $J$로는 학습하려는 비디오의 noisy version, $C$로는 clean video의 마스크된 버전을 넣어서 파인튜닝 하였다고 합니다. 이를 통해 모델이 마스킹된 콘텐츠만 애니메이션을 적용하면서 C의 마스킹되지 않은 정보를 출력 비디오에 복사하는 방법을 학습할 수 있었다고 합니다.
4-3. Image-to-Video
해당 모델은 이미지를 비디오로 변환 할 수도 있습니다. 이를 위해 비디오의 첫 번째 프레임을 입력으로 줍니다. Conditioning signal인 $C$에는 이 첫 번째 프레임과 나머지 비디오에 대한 빈 프레임이 포함 되도록 합니다. 마스크 $M$에는 첫 번째 프레임에 대해 1(마스킹 되지 않음)을 포함하고 나머지 비디오에 대해서는 0(마스킹 됨)을 포함하도록 합니다.
이를 통해 원하는 첫 프레임으로 시작하여 전체 동영상 길이에 걸쳐 복잡하고 일관된 움직임을 보이는 동영상을 생성하다고 합니다.
4-4. Inpainting
해당 모델은 Inpainting도 가능합니다. 이를 위해 conditioning signal로 사용자가 제공한 비디오 $C$와 비디오에서 완성할 영역을 나타내는 마스크 $M$를 넣어 줍니다. 이를 통해 물체를 바꾸거나 삽입하고 특정 영역을 편집하는데에 사용될 수 있다.
Inpainting 결과는 아래와 같습니다. 

4-5. 시네마그래프
해당 모델은 이미지의 특정 영역에 대해 애니메이션을 적용할 수도 있습니다. 이를 위해 conditinal signal로 전체 비디오에 대해 복제된 입력 이미지를 넣어주고, 마스크 $M$에는 첫 번째 프레임 전체에 대한 마스크가 포함되며(마스크가 해제 됨), 다른 프레임의 경우는 사용자가 제공한 영역 외부에만 마스크가 적용될 수 있도록 합니다.
그 결과는 아래와 같습니다.

5. 평가 및 비교
이제 해당 모델에 대한 성능 평가 방법과 결과에 대해 설명드리겠습니다. 실험 설정은 아래와 같습니다.
- 훈련 데이터
- 텍스트 캡션이 있는 3000만개의 동영상 데이터로 훈련
- 동영상은 16fps(5초), 80 프레임 길이
- Resolution
- 베이스 모델은 128x128로 훈련된다.
- SSR은 1024x1024 프레임을 출력한다.
- 테스트 데이터
- 다양한 사물과 장면을 설명하는 113개의 텍스트 프롬프트 모음으로 테스트
- 수집한 18개의 프롬프트와 이전 연구에서 사용한 95개의 프롬프트로 구성된다.
- UCF101 데이터 세트은 제로 샷 성능을 평가하는데 사용
베이스라인
비교할 베이스라인은 아래와 같습니다.
- 베이스라인 모델
- ImagenVideo
- AnimateDiff
- StableVideoDiffusion
- ZeroScope
- Pika
- 2세대 RunawayML
- 특이 사항
- AnimateDiff와 ZeroScope은 각각 오직 16프레임, 36프레임만을 출력한다.
- StableVideoDiffusion은 25 프레임을 출력하고, 텍스트에 대한 조건이 없는 이미지-비디오 모델이다.
정성적 평가
베이스라인과 본 논문에서 제안한 모델의 결과를 정성적으로 평가한 결과는 아래와 같습니다. 
각 베이스라인 별로 보이는 특성은 아래와 같았다고 합니다.
- 2세대 RunawayML과 Pika는 프레임당 높은 화질을 보여주지만, 제한된 모션으로 인해 거의 정적인 비디오가 생성되었다고 합니다.
- ImagenVideo는 적당한 양의 모션을 생성하지만 전반적인 시각적 품질이 낮았다고 합니다.
- AnimateDiff와 ZeroScope는 눈에 띄는 움직임을 보여주지만 시각적 아티팩트가 발생하기 쉽고, 짧은 길이의 비디오만을 생성할 수 있었다고 합니다.
반면 제안한 방법에서는 시간적인 일관성과 전반적인 품질을 유지하면서 모션 크기가 큰 5초짜리 동영상을 생성할 수 있었다고 합니다.
정량적 평가
모델 성능을 정량적으로 평가하기 위해 UCF101 데이터셋에 대해 제로샷 평가를 하였고, 실제 사용자를 통해 정량적인 평가도 하였다고 합니다.
먼저 UCF101에 대한 제로샷 평가 결과는 아래와 같습니다. 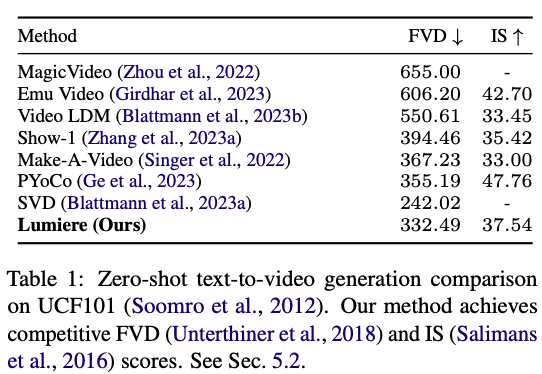
본 논문에서 제안한 방법이 FVD와 IS 측면에서 모두 좋은 성능을 보였다고 합니다. 하지만 알려진대로 이러한 지표는 실제 사람의 인식을 충분히 반영하지는 못하기 때문에 사용자 평가도 진행 하였습니다.
사용자 평가 방법은 다음의 과정으로 진행하였습니다.
- 참가자들에게 무작위로 선택된 한 쌍의 비디오를 제시한다.
- 하나는 본 논문에서 제안하는 모델에 의해 생성된 비디오고 다른 하나는 기본 방법 중 하나로 생성된 비디오
- 참가자들에게 시각적 품질과 움직임 측면에서 더 낫다고 생각되는 비디오를 선택하게 하고, 텍스트 프롬프트와 더 일치하는 비디오를 선택하도록 하였다.
- 각 기준과 질문에 대해 약 400건의 사용자 평가를 수집했다.
이렇게 평가한 결과로는 아래와 같습니다.
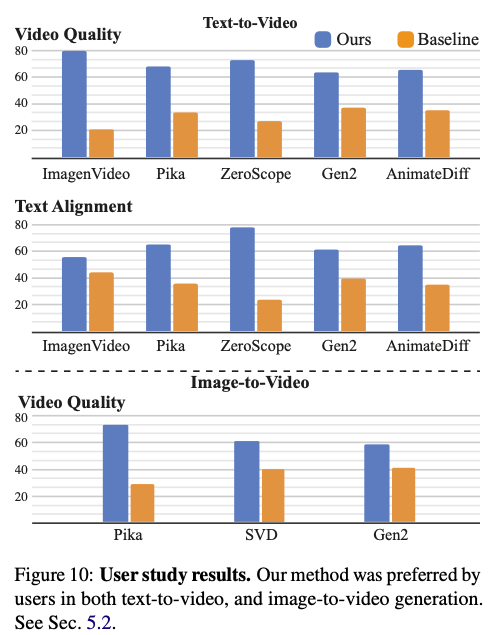
모든 지표에 대해서 사용자들이 본 논문에서 제안한 방법으로 생성한 비디오가 더 낫다고 평가하였다고 합니다.
6. 결론
본 논문에서는 서로 떨어진 키프레임을 생성한 후 보간하는 일반적인 접근 방식으로 인해 생성된 결과가 일관된 동적을 만들지 못한다는 문제점을 해결하였습니다. 해당 문제를 해결하기 위해 공간 및 시간적 다운샘플링과 업샘플링 모듈을 통합하여 full-frame-rate 비디오를 바로 만드는 U-Net 구조를 제안하였고, 그 결과 SOTA 성능을 냈으며 다양한 어플리케이션에 해당 모델이 적용될 수 있음을 보였다.
다만 현재 모델은 여러 장면으로 구성되거나 장면 간 전환이 있는 동영상을 생성하도록 설계되지 않았고, SSR 모듈은 여전히 필요하다는 점이 있습니다. 이와 관련해서 추후 연구할 거리가 남아있다고 합니다.
또한 해당 기술이 가짜 콘텐츠나 유해한 콘텐츠를 만드는 데 악용될 위험이 있으며, 해당 사례를 탐지할 수 있는 도구를 개발하고 적용하는 것이 중요하다는 것으로 논문을 마무리 지었습니다.
느낀점
Make-a-Video에서는 어플리케이션 부분에 대한 설명이 부족했는데 해당 논문에서는 그 부분에 대해서는 설명을 많이 해줬던 것 같습니다. 하지만 전체적인 모델 구조에 대해서는 친절하게 설명이 되진 않은 것 같은 느낌이 있었습니다.
또한 기존 방식들이 TSR 방법을 도입한 이유는 메모리적인 한계가 크다고 생각하는데, 해당 방법에서는 아무리 공간축/시간축에 대해서 다운샘플링을 했다고 하더라도 원하는 길이의 동영상을 생성하기 위해서는 매우 큰 메모리가 필요할 것으로 예상 됩니다.
그리고 결국엔 SSR 모델의 한계로 인해 각 프레임들이 segment로 나눠지기 때문에 일관적인 동영상 생성을 위해서 제안한 STUNet의 효과가 희석되지 않나 싶기도 합니다. STUNet을 도입함으로써 기존 방식보다 많은 비용이 더 필요할 것으로 예상 되는데 그 비용에 비해 효과가 얼마나 의미 있는지 이 부분이 궁금해졌습니다.
해당 모델이 그럴 듯한 성능을 낼 수 있을 정도로 학습 시키기 위해서 얼마 만큼의 데이터가 필요한지, 메모리는 얼마나 필요한지, 학습 시간은 얼마나 되고 추론 시간은 어떻게 되는지에 대한 정보가 하나도 없어서 아쉽긴 했습니다.