[논문리뷰] Synthetic Data from Diffusion Models Improves ImageNet Classification
이번에 리뷰할 논문은 구글 리서치 그룹에서 TMLR(Transactions on Machine Learning Research) 2023에 제출한 논문인 Synthetic Data from Diffusion Models Improves ImageNet Classification입니다.
생성 모델이 놀라운 속도로 발전하고 있는데요! 해당 논문에서는 생성 모델의 수준이 얼만큼 왔는지, 복잡한 이미지 데이터인 ImageNet 데이터에 대해서도 충분한 퀄리티의 데이터를 생성할 수 있는 정도가 되었는지, 그래서 이 생성된 데이터를 augment된 데이터로 사용할 수 있는 정도까지 왔는지에 대한 실험과 답을 제시합니다. 이 글의 목차는 논문 내용과 동일하게 구성하였습니다.
💡 핵심 요약
Classification task에서 생성 모델을 데이터 augmentation으로 사용해 분류 성능을 개선 시킴
Large-scale text-to-image diffusion 모델을 fine-tuning하여 FID와 Inception Score, Classification Accuracy Score에서 SOTA를 달성
ImageNet에 대해 fine-tuning된 Imagen 모델을 사용함
Diffusion으로 만든 합성 데이터를 학습에 사용하였을 경우 ResNet 및 Vision Transformer의 분류 성능이 크게 향상 됨
본 논문에서는 기술적으로 엄청 새로운 내용은 없는데요! 다만 보통 사전학습된 text-to-image diffusion 모델을 사용하던 기존 방법들과는 달리 Imagen을 ImageNet에 대해 파인튜닝 했다는 것이 새롭습니다.
1. Introduction
Diffusion 모델의 등장으로 생성 기술이 크게 발전되었습니다. 현재 생성 기술 수준이 data augmentation으로 사용될 수 있을 만큼의 자연스러운 이미지를 생성하는 것도 가능할까?에 대한 질문이 나오는 것은 당연하고, 본 논문에서는 이에 대한 답을 찾고자 했습니다. 먼저 이 질문에 대한 답을 이야기 하면 아래와 같습니다.
- 결과 요약
- ImageNet에 대해 fine-tuning된 Imagen이 FID, Inception Score, CAS 성능에 대해 SOTA 성능을 달성 하였다.
- 합성 데이터와 실제 데이터를 결합하여 사용하고, 합성 데이터의 양이 많고, 훈련 시간이 길수록 생성 데이터로 훈련된 모델의 성능이 더욱 향상되었다.
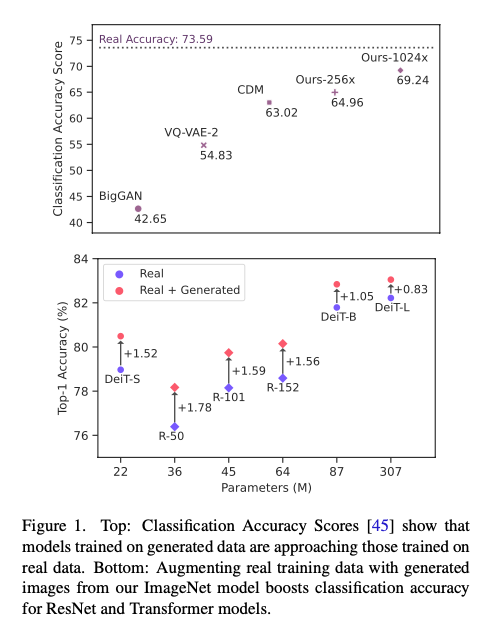 위 그림: 합성 데이터로만 학습된 모델 분류 성능과 진짜 데이터로 학습된 모델의 분류 성능 비교, 아래 그림: 합성 및 진짜 데이터를 사용하였을 때의 분류 성능과 진짜 데이터로 학습된 모델의 분류 성능 비교
위 그림: 합성 데이터로만 학습된 모델 분류 성능과 진짜 데이터로 학습된 모델의 분류 성능 비교, 아래 그림: 합성 및 진짜 데이터를 사용하였을 때의 분류 성능과 진짜 데이터로 학습된 모델의 분류 성능 비교
위의 그림에서 볼 수 있듯이 합성 데이터로만 학습한 모델의 정확도와 실제 데이터로 학습한 모델의 정확도를 비교했을 때, 다른 모델들에 비해 본 논문에서 제안한 모델이 훨씬 성능 차이가 적다는 것을 알 수 있습니다. 또한, 아래 그림을 보면, 실제 데이터와 생성된 데이터를 더해서 학습했을 경우에는 ResNet 기반 모델과 Transformer 기반 모델들에서 모두 실제 데이터를 사용했을 때보다 성능 향상이 있었습니다.
2. Related Work
생성 모델을 이용해 data augmentation을 하려고 했던 기존 방법들에 대해 짧게 이야기 햐려고 합니다. 최근에는 large-scale text-to-image 모델들이 학습 데이터를 보강하는데 사용되기 시작했습니다.
그 예로 “Is synthetic data from generative models ready for image recognition?” 논문이 있습니다. 해당 논문에서는 GLIDE로 생성된 합성 데이터가 zero-shot과 few-shot 이미지 분류 성능을 향상 시켰으며, CIFAR-100 이미지에서 GLIDE를 fine-tuning하여 생성된 합성 데이터 세트가 CIFAR-100의 분류 정확도를 크게 향상 시켰다고 이야기 합니다.
하지만, 위의 논문을 포함해서 기존의 논문들은 이런 생성 모델을 이용해서 data augmentation을 하여도 ImageNet validation set에 대해서는 성능을 향상 시키지 못했습니다. 또한, 기존에 논문들은 pretrained Stable Diffusion 모델을 사용하고, fine-tuning은 하지 않았습니다. 본 논문에서는 기존 논문들과는 다르게 Imagen을 ImageNet에 잘 동작하고 fine-tuning을 하였고, 그 결과 ImageNet validation set에 대해서도 성능을 향상 시킬 수 있었습니다.
3. Background
본 논문에서는 Classification Accuracy Scores(CAS)라는 성능 지표를 소개합니다. FID와 Inception Score는 생성 모델의 성능 지표로 워낙 많이 쓰여서 설명은 생략하고, CAS에 대해서는 논문에서 써져 있는 내용으로 소개하겠습니다.
CAS는 FID와 Inception Score와 마찬가지로 생성 모델이 만들어낸 샘플의 품질을 평가하는 방법으로 제안 된 성능 지표입니다. 이것은 ‘합성 데이터’로만 훈련된 ResNet-50 모델에 대한 ImageNet validation set에 대한 분류 성능을 의미합니다. 먼저, 생성 모델을 통해 ImageNet 데이터에 대한 합성 데이터를 만들어냅니다. 그리고 이 합성 데이터만을 이용하여 ResNet-50을 훈련 시키고, 그 훈련된 모델의 실제 ImageNet validation set에 대해 분류 성능이 CAS가 됩니다. 만약 합성 데이터가 실제 ImageNet과 비슷하다면 그 합성 데이터로 학습된 모델은 실제 ImageNet validation set에 대해 좋은 분류 성능을 보일 것이라는 가정을 이용한 성능 지표라고 이해하면 될 것 같습니다.
저자에 의하면 그동안 생성모델의 CAS 성능은 좋지 않았다고 합니다. 생성된 샘플로만 훈련된 모델은 실제 데이터로 훈련된 모델보다 성능이 떨어졌고 (이는 당연해보입니다), 실제 데이터에 합성 데이터를 추가하면 성능이 떨어졌다고 합니다. 이는 아마도 생성된 샘플의 품질, 다양성 등이 원인일 수 있을 것이라고 합니다.
4. Generative Model Training and Sampling
여기서는 실제로 저자들이 어떻게 text-to-image diffusion 모델을 학습하고, 샘플링을 하였는지에 대한 설명을 합니다.
먼저 저자들은 text-to-image diffusion 모델로는 Imagen을 사용하였습니다. Text-to-image 모델을 어떻게 ImageNet 클래스와 alignment 할 지에 대한 고민이 필요했다고 합니다. 처음에는 CLIP에서 사용한 방법과 유사하게 짧은 텍스트를 ImageNet 클래스의 텍스트 프롬프트로 사용했다고 하였는데 이 경우에 성능이 좋지 않았다고 합니다. 이는 Imagen에서 high guidance weight를 사용하여 샘플의 다양성이 저하 되면서 생기는 현상일 수 있다고 합니다. 따라서, 저자들은 프롬프트를 한 두단어 클래스 이름으로 수정하고, 모델의 weight와 sampling parameter를 fine-tuning 했다고 합니다.

왼쪽 그림이 fine-tuning이 적용된 Imagen이 만들어낸 이미지고, 오른쪽이 fine-tuning이 적용되지 않은 Imagen입니다. 아래에서 두 번째 클래스인 Schipperke를 보면, 이것은 스키퍼키라는 개 품종을 의미하는데 fine-tuning이 적용되지 않은 Imagen의 경우는 꽃과 같은 전혀 엉뚱한 이미지를 만들고 있는 것을 볼 수 있습니다.
4.1. Imagen Fine-tuning
이 부분은 Imagen을 어떻게 fine-tuning 했는지를 설명하는 부분입니다.
먼저 Imagen 구조는 아래와 같습니다.
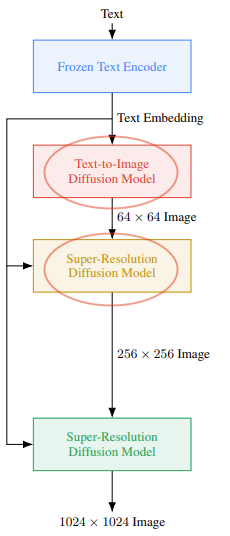
본 논문에서는 위의 Imagen 구조에서 빨간 원으로 표시된 부분에 대해서만 fine-tuning 했습니다. Frozen Text Encoder의 경우는 원래 Imagen에서도 학습을 하지 않는 부분이라 마찬가지로 학습을 하지 않았고, 1024x1024 Image를 출력으로 하는 마지막 Super-Resolution Diffusion Model의 경우 ImageNet에 고해상도의 데이터가 적어서 fine-tuning을 하지 않았다고 합니다.
64x64 모델의 경우는 210K step 정도 학습하였고, optimizer의 경우는 Imagen에서 사용하였던 Adafactor optimizer를 사용하였다고 합니다. 64x64 → 256x256 super-resolution 모델의 경우는 490K step 정도 하였고, Adam optimizer를 사용하였다고 합니다.
최적의 모델 선택의 기준으로는 기본 Imagen sampler와 ImageNet-1K validation set에 대해 10K개의 샘플들에 대해 FID score를 계산했을 때 가장 좋은 성능의 모델을 선택했다고 합니다.
4.2. Sampling Parameters
이 부분은 본 논문에서 sampling parameter는 어떻게 정했는지를 설명하는 부분입니다. 먼저, Text-conditioned diffusion model 샘플링의 품질, 다양성, 속도는 디퓨전 스텝 수, noise condition augmentation, guidance weight for classifier-free guidance, log-variance mixing coefficient 등에 대해 큰 영향을 받는다고 합니다.
각각에 대해 간단하게 설명하면 아래와 같습니다.
Noise condition augmentation:
이미지 생성 과정에서 확률적인 요소를 도입하여 생성된 이미지의 다양성을 증가시키는 기술. 일반적으로, 모델은 잠재 공간의 랜덤한 노이즈를 입력으로 받아 다양한 이미지를 생성하게 됨. 이것은 생성된 이미지가 조금씩 다른 것으로 보이게 만들며, 더 다양한 결과를 얻을 수 있게 함 (자세한 내용은 “Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding“를 참고해주세요)
Guidance weight for classifier-free guidance:
“Classifier-free guidance”는 이미지를 생성하는 데 분류기나 특정 지표 없이 외부 정보를 사용한다는 것. “Guidance weights”는 외부 정보를 모델에 어떻게 반영할지를 조절하는 가중치를 의미할 수 있으며, 이러한 가중치를 조절하여 모델이 원하는 특성이나 스타일을 가진 이미지를 더 잘 생성하도록 함 (자세한 내용은 “Classifier-free diffusion guidance“를 참고해주세요)
Log-variance mixing coefficient:
이미지 생성 모델에서 사용되는 확률 분포의 변동성을 조절하는 데 사용되는 계수를 나타냄. 이미지 생성 모델은 일반적으로 확률 분포를 사용하여 이미지를 생성하며, 이 확률 분포의 평균과 분산을 조절함으로써 생성된 이미지의 다양성과 품질을 조절할 수 있음. 로그-분산 혼합 계수는 이러한 분산을 조절하는 데 사용되며, 높은 값은 더 큰 분산을 의미하고, 작은 값은 더 작은 분산을 의미함. 이를 통해 이미지 생성의 다양성을 조절할 수 있음 (자세한 내용은 “Improved denoising diffusion probabilistic models“를 참고해주세요)
64x64 기반 모델의 샘플링 parameter 설정법에 대해 설명하겠습니다. 해당 모델의 샘플링 이미지 샘플링의 전반적인 특징과 다양성의 영향을 주게 됩니다. 1차 sweep으로 DDPM 샘플러를 이용하여 FID-50K에 대해 가장 최적의 하이퍼파라미터를 찾습니다. Sweep의 사용한 각 하이퍼파라미터의 범위는 아래와 같습니다.
- Guidance weight: [1.0, 1.25, 1.5, 1.75, 2.0, 5.0]
- Log-variance: [0.0, 0.2, 0.3, 0.4, 1.0]
- Denoise step: [128, 500, 1000]
1차 sweep 결과 최적의 FID는 log-variance는 0이고 denoising step은 1000이었을 때라고 합니다.
1차 sweep이 끝난 후에는 guidance weight에 대해서만 sweep을 합니다. 이 때에는 1.2M 이미지를 사용하고, 각 guidacne weight에 대해 FID, IS, CAS를 측정했다고 합니다.
각 샘플링 하이퍼파라미터에 대한 실험 결과는 아래와 같습니다.
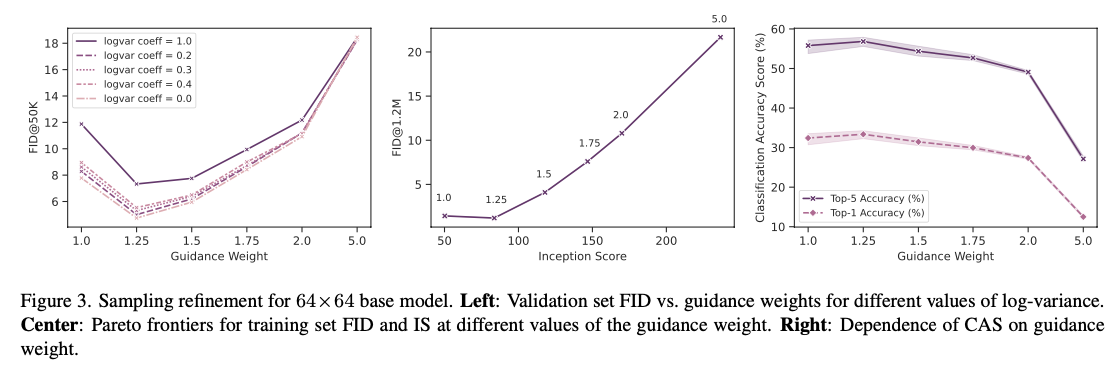 왼쪽 그림이 1차 sweep에 대한 결과고, 가운데와 오른쪽 그림이 2차 sweep에 대한 결과로 guidance weight에 따른 FID, IS, CAS를 나타낸 결과입니다.
왼쪽 그림이 1차 sweep에 대한 결과고, 가운데와 오른쪽 그림이 2차 sweep에 대한 결과로 guidance weight에 따른 FID, IS, CAS를 나타낸 결과입니다.
이제 다음으로는 64x64 → 256x256 super-resolution 모델에 대해 하이퍼파라미터를 선택하는 부분에 대해 설명하겠습니다. 하이퍼파라미터의 range는 아래와 같습니다.
- Guidance weight: [1.0, 2.0, 5.0, 10.0, 30.0]
- Noise conditioning augmentation: [0.0, 0.1, 0.2, 0.3, 0.4]
- Log-variance mixing coefficients: [0,1, 0.3]
- Denose steps: [129, 500, 1000]
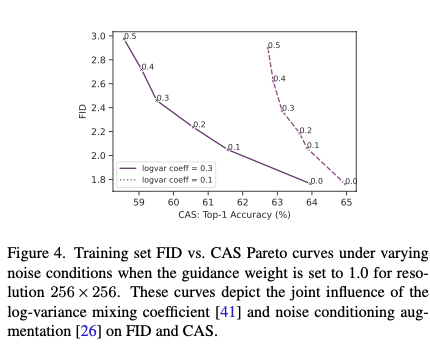
위 그래프는 guidance weight를 1.0으로 설정하고 noise condition 파라미터를 변경했을 때 FID와 CAS의 그래프를 나타낸 그래프입니다. CAS 같은 경우는 logvar coeff가 0.3일 때 전반적으로 좋은 성능을 보였으며, FID 같은 경우도 logvar coeff가 0.3일 때 전반적으로 좋은 성능을 보인 것을 알 수 있습니다.
샘플링 하이퍼파라미터의 결과를 분석해보자면, 전반적으로 FID와 CAS는 높은 상관관계가 있으며 (Figure 4 참고), guidance weight가 작을수록 CAS는 높아지지만, Inception Score에는 부정적인 영향을 주며 (Figure 3 참고), noise augmentation이 0일 때 FID가 가장 작은 것을 볼 수 있습니다. (Figure 4 참고)
이런 하이퍼파라미터 설정 방법을 기준으로 본 논문에서 최종적으로 설정한 값은 아래와 같다고 합니다.
- Guidance weight
- 베이스 모델: 1.25
- 나머지 resolution: 1.0
- Log-variance mixing coefficients (sampler, steps)
- 64x64 샘플: 0.0 (DDPM, 1000 denoising steps)
- 256x256 샘플: 0.1 (DDPM, 1000 denoising steps)
- 1024x1024 샘플: 0.0 (DDIM, 32 denoising steps)
4.3. Generation Protocol
이 부분은 실제로 데이터 합성은 어떤 프로토콜을 따랐는지에 대해 설명하는 부분입니다. 본 논문에서는 원본 데이터셋의 class balance를 유지하며 데이터를 합성했으며, 합성된 결과 총 훈련 데이터셋의 규모는 1배인 1.2M 에서 10배인 12M 규모의 데이터셋의 범위를 가지도록 데이터를 합성했다고 합니다.
5. Result
5-1. Sample Quality: FID and IS
먼저, 합성된 데이터의 품질을 합성 태스크에서 많이 사용되는 지표인 FID와 IS의 관점으로 봅니다.
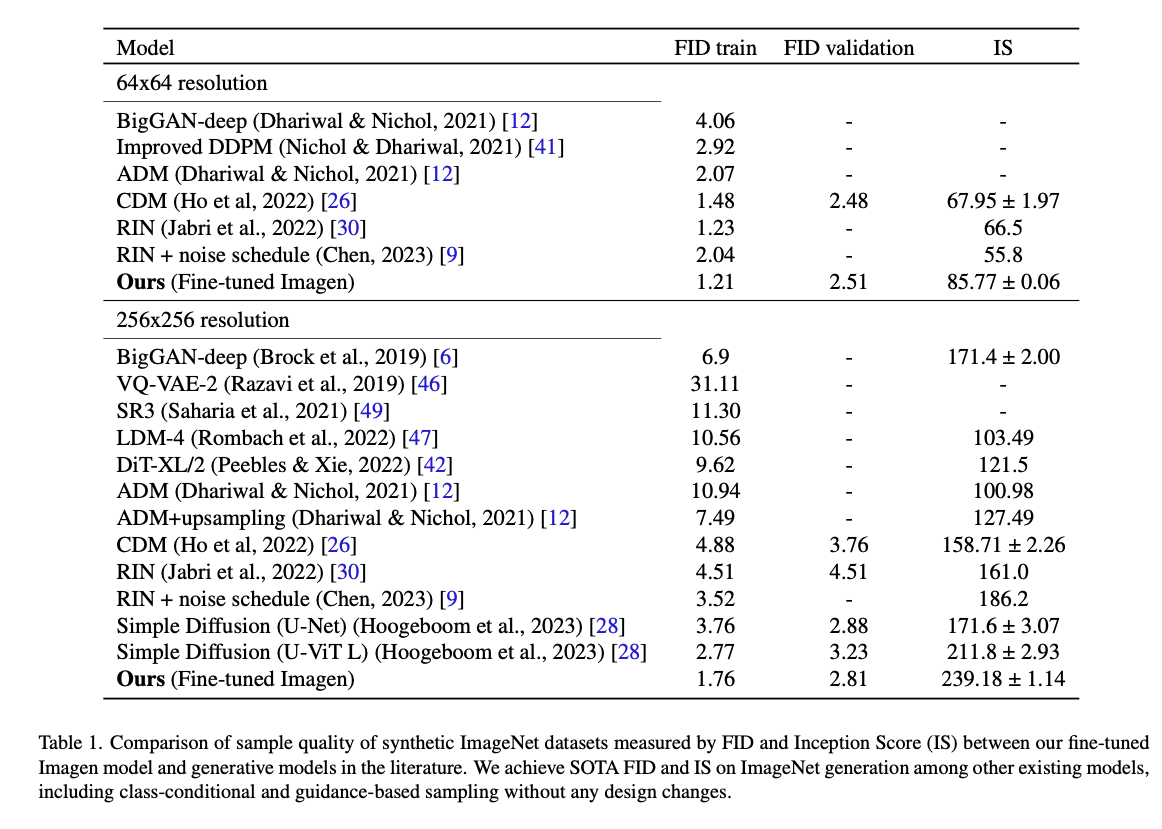
위 표에서 볼 수 있듯이, 본 논문의 파인 튜닝된 Imagen이 ImageNet에 대한 데이터 생성에 대해 다른 베이스모델들 보다 FID와 IS가 뛰어난 것을 알 수 있습니다. 이는 64x64 resolution과 256x256 resolution에서 모두 해당되었습니다.
5.2. Classification Accuracy Score
이 부분은 CAS 성능 지표를 통해 본 논문에서 제안한 모델의 데이터 합성 능력을 확인하는 부분입니다. 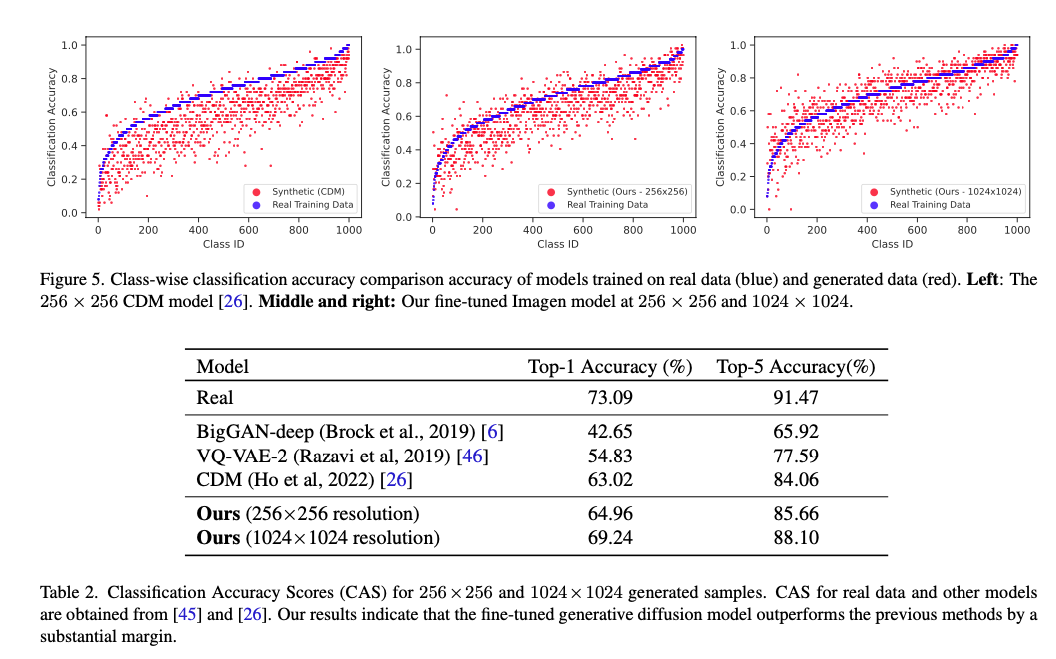
Figure 5에서 파란색 부분은 실제 학습 데이터로 학습된 모델의 분류 성능이고, 빨간색 부분은 합성된 데이터로 학습된 모델의 분류 성능입니다. 왼쪽 그림은 베이스라인 중 하나인 CDM 모델의 성능을 나타낸 그림이며, 가운데는 본 논문에서 256x256 resolution 모델의 성능, 오른쪽은 본 논문에서 제안한 1024x1024 resolution 모델의 성능을 나타낸 것입니다. 빨간색 부분이 파란색 부분보다 전반적으로 위쪽에 위치하면 모델의 성능이 좋다고 해석할 수 있습니다. 이 그림을 통해 본 논문에서 제안한 모델들이 베이스라인보다 좋은 성능을 보인다는 것을 알 수 있습니다.
Table 2에서도 마찬가지로 본 논문 모델이 다른 베이스 모델보다 성능이 뛰어난 것을 알 수 있습니다. 여기서 주목할 만한 점은 CAS를 평가하기 위한 ResNet50이 256x256으로 입력 데이터를 다운샘플링 함에도 1024x1024 샘플에 대한 결과가 훨씬 좋다는 것을 볼 수 있습니다. (Ours 256x256 resolution보다 Ours 1024x1024 resolution의 CAS 성능이 월등히 높음)
5.3. Classification Accuracy with Different Models
이 부분은 합성된 데이터를 여러 종류의 모델로 학습 시켰을 때, 각 모델의 분류 성능을 확인하는 부분입니다. CAS와 비슷하지만 CAS에서는 ResNet50 모델로 분류 성능을 확인했지만 여기서는 ResNet50 이외에 모델로도 분류 성능을 본다는 차이점이 있습니다.
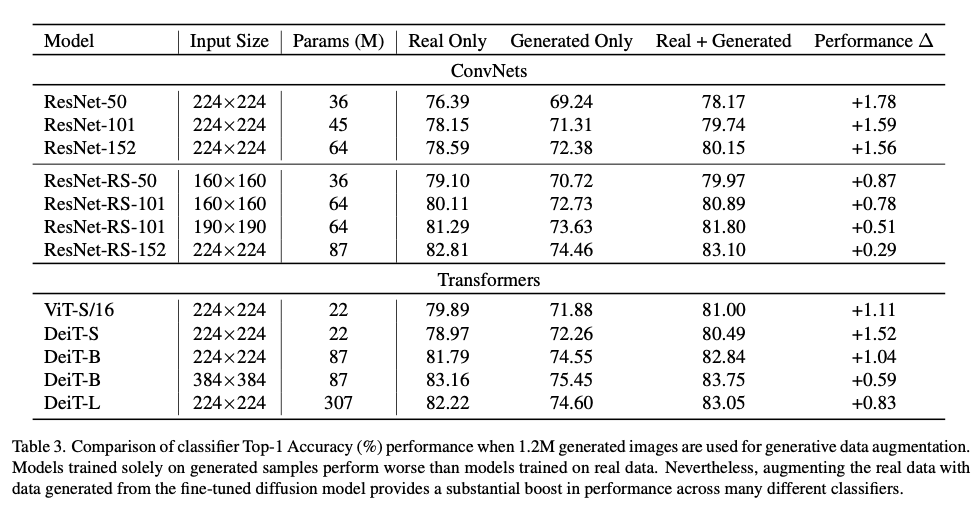
위 표에서 확인할 수 있듯이, 다양한 모델에 대해서 분류 정확도를 살펴본 결과 생성된 데이터로만 학습될 경우에는 실제 데이터로 학습할 때 보다 성능이 낮았지만, 실제 데이터와 생성된 데이터를 합쳐서 학습할 경우 실제 데이터만 사용했을 때보다 성능이 증가한 것을 볼 수 있습니다. 이것은 onvNet기반 모델과 transformer 기반 모델에 대해서 동일한 양상을 보였습니다.
5.4. Merging Real and Synthetic Data at Scale
이 부분은 합성 데이터 규모에 따른 ResNet-50의 성능을 분석한 부분입니다.
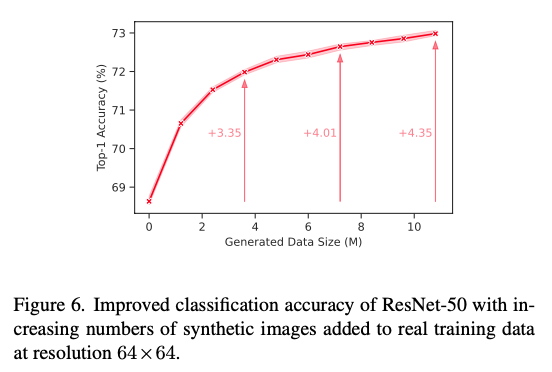
64x64 이미지의 경우 생성되는 데이터의 양이 증가함에 따라 성능이 지속적으로 향상되는 것을 볼 수 있습니다.
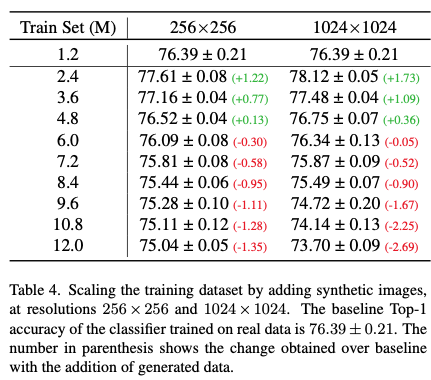
하지만 다른 resolution에 대해서는 다른 양상을 보였습니다. 학습 데이터가 4.8M 규모가 될 때까지는 합성 데이터를 추가하는 것이 분류 성능에 좋았으나, 합성 데이터를 더 늘려 그 이상의 규모가 되었을 때는 오히려 성능이 떨어지는 것을 볼 수 있었습니다.
6. Conclusion
본 논문에 결론 부분을 보자면, 이 논문에서는 Large-sclae text-to-image diffusion 모델을 파인튜닝하여 FID, Inception Score, CAS 성능 지표에 대해서 SOTA를 달성했습니다.
- FID: 1.76 at 256x256
- Inception Score: 239 at 256x256
- CAS: 64.96 for 256x256, 69.24 for 1024x1024
또한 그렇게 생성 데이터를 이용하여 ResNet과 Transformer 기반 모델들에 대한 ImageNet classification accuracy를 향상 시켰습니다.
실험 결과에 대해서 생각해볼만한 거리들이 있었는데 그 중 하나는 CAS 성능 측정할 때 ResNet50이 입력을 256x256으로 다운샘플링 함에도 불구하고 256x256보다 1024x1024의 모델의 CAS가 좋은 것이 있었습니다. 이는 다운샘플링을 하더라도 다운샘플링 전 원본 데이터 resolution이 클 때 더 많은 정보를 담는다는 것을 의미하는 것일 수 있습니다. 또한, 64x64 데이터에서 합성 데이터의 양이 증가함에 따라 분류 정확도가 지속적으로 증가했지만 고해상도 데이터에서는 그렇지 않았던 것을 통해 고해상도에 이미지에 대해서는 보다 정교한 훈련 방법이 필요할 수 있음을 시사하고 있습니다.
이렇게 Synthetic Data from Diffusion Models Improves ImageNet Classification 논문의 리뷰를 마치겠습니다. 개인적으로 느낀 점은 실제 산업에서는 data shortage나 class imbalance 문제가 대부분 발생하는데 본 논문이 그 해결법 중 하나가 될 수 있을 것 같다는 생각이 들었습니다. 다만 Frozen Text Encoder는 추가적으로 파인튜닝이 되지 않기 때문에 특정 산업에서만 쓰이는 특정 텍스트가 들어왔을 때는 잘 동작할 수 있을까 하는 의문이 들었습니다. 또한 합성하고자 하는 데이터셋에 맞게 파인튜닝을 해야하는 점이 꽤나 불편할 것 같아서 파인튜닝이 모델 성능에 얼마나 큰 의미를 갖는지, 파인튜닝을 하지 않았을 때의 CAS 성능도 논문에 있었으면 좋았을 것 같다는 개인적인 생각이 들었습니다. (물론 Figure 2를 보고 어느 정도 결과를 유추해볼 순 있지만요!)
이 페이지는 가짜연구소 Text-to-Image Generation (feat. Diffusion) 페이지에서도 볼 수 있습니다. Github 저장소에도 많은 관심 부탁드려요!