[논문리뷰] DiffuScene: Denoising Diffusion Models for Generative Indoor Scene Synthesis
안녕하세요! 오늘은 CVPR 2024에 발표된 3D 실내 장면을 생성하는 AI 모델인 DiffuScene에 대해 이야기해보려고 합니다. 이 모델은 Denoising Diffusion Models 활용하여 실내 공간을 자동으로 디자인하는데, 객체의 위치, 크기, 방향, 의미, 기하학적 특징 등을 조합해 더 현실적이고 자연스러운 장면을 만들어 내는 모델 입니다. 간단하게 핵심 개념을 먼저 말씀 드리면, 장면을 여러 객체들의 집합으로 구성하고, 각 객체를 속성들로 나타내서, 그 속성들의 feature들을 디퓨전 모델에 넣어서 3D 장면을 생성하는 것입니다! 이를 통해 장면 생성 뿐 아니라 아래의 다양한 응용이 가능합니다!
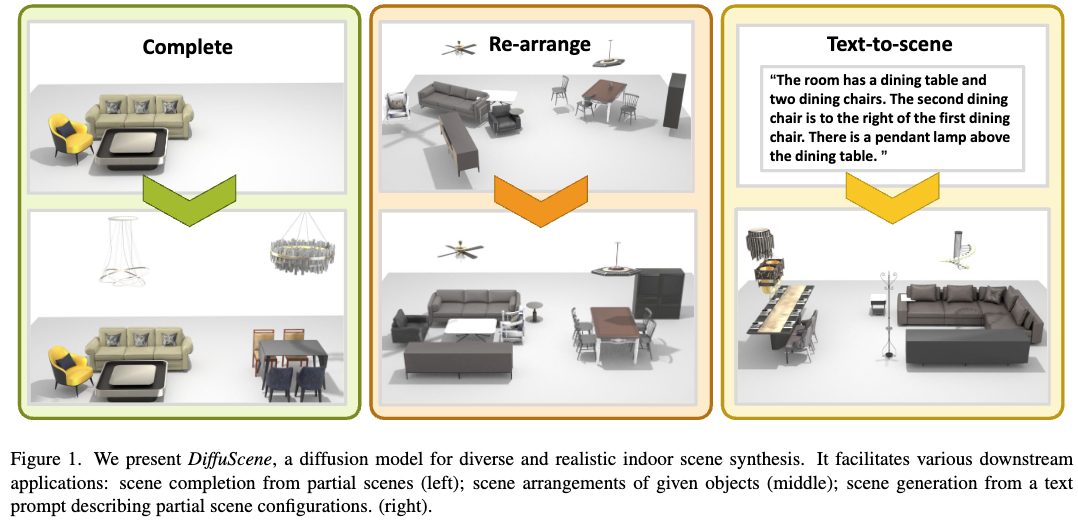
DiffuScene이란?
DiffuScene은 3D 공간에서 객체의 배치, 기하학적 특징, 의미론적 요소를 학습하여 실내 장면을 자동으로 생성하는 모델입니다. 기존의 GAN이나 VAE 같은 생성 모델과 비교했을 때, 더 정교한 장면을 만들어낼 수 있다는 점이 강점입니다.
이 모델의 주요 특징은 다음과 같습니다:
- 3D Scene Denoising Diffusion 모델
- 기존의 2D 기반 모델이 아니라, 3D 공간에서 직접 객체를 배치하고 생성할 수 있습니다.
- 예를 들어, 가구들이 자연스럽게 배치된 거실이나 사무실 공간을 생성할 수 있습니다.
- Geometry Retrieval을 활용한 Shape Latent Feature Diffusion
- 모델이 객체 간의 관계를 인식하여 더 자연스러운 공간을 형성할 수 있도록 합니다.
- 예를 들어, 의자가 테이블 주변에 알맞게 배치되도록 학습하는 것입니다.
- 다양한 응용 가능성
- 주어진 부분 장면을 완성(Completion)
- 기존 장면을 재배치(Re-arrange)
- 텍스트 기반으로 실내 장면을 생성(Text-to-Scene)
이제 DiffuScene이 어떻게 작동하는지 좀 더 자세히 살펴보겠습니다.
기존 방식과의 차이점
과거에는 실내 장면을 생성하는 방법이 크게 두 가지로 나뉘었습니다.
- 전통적인 방식:
- 데이터 기반 최적화를 통해 장면을 생성했습니다.
- 객체 빈도 분포, 인간 행동 패턴(Affordance Map), 기존 공간 배치 예시 등을 참고해 장면을 구성했습니다.
- 딥러닝 기반 방식:
- GAN(생성적 적대 신경망), VAE(변분 오토인코더), Autoregressive 모델 등을 활용하여 공간을 생성했습니다.
그럼에도 불구하고, 기존 방법들은 한계가 있었습니다. 장면이 비현실적이거나 객체 간의 관계를 제대로 학습하지 못한다는 문제점이 있었습니다.
이 문제를 해결하기 위해 3D Diffusion Models이 등장했고, DiffuScene은 이러한 기술을 한 단계 더 발전시켰습니다.
기존 3D Diffusion 모델과 비교하면 DiffuScene의 장점은 다음과 같습니다:
- 더 다양한 모달리티(조건)를 활용할 수 있음 → 다양한 입력을 통해 더욱 풍부한 3D 장면을 생성 가능
- 객체 배치의 대칭성을 더 잘 학습함 → 테이블 주위에 의자를 배치할 때, 더 자연스러운 배치 가능
DiffuScene의 핵심 개념: Object Parametrization
DiffuScene은 3D 실내 장면의 객체 속성 분포를 학습하는 Diffusion 모델이라고 볼 수 있습니다. 실내 장면은 바닥 중심에 원점을 두고, 월드 좌표계에서 위치한다고 가정했으며, 각각의 장면 $S$는 $N$개의 객체들로 구성된다고 가정했습니다. 각 장면을 순서가 없는 $N$개의 객체들의 집합으로 나타냈으며, 각 객체를 다음과 같은 속성으로 표현합니다:
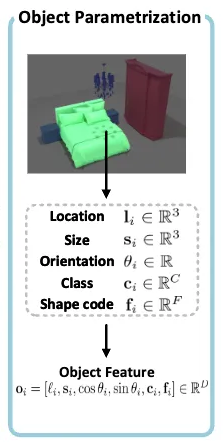
- 클래스 카테고리 $\mathrm{c} \in \mathbb{R}^C$ → 예: 소파, 책상, 의자 등
- 객체 크기 $\mathrm{s} \in \mathbb{R}^3$
- 위치 $\mathbf{l} \in \mathbb{R}^3$
- 수직 축 주위의 회전 각도 $\theta \in \mathbb{R}$ → 회전 각도는 코사인 및 사인값의 2차원 벡터로 파라미터화하여 표현
- Shape code $\mathrm{f} \in \mathbb{R}^F$ → 사전 학습된 Shape Autoencoder에서 추출
이 속성들을 모두 연결하면 객체 하나를 다음과 같이 표현할 수 있습니다:
각 장면은 여러 개의 객체로 이루어지기 때문에, 객체 수를 맞추기 위해 ‘빈’ 객체를 패딩으로 추가하기도 합니다.
DiffuScene의 핵심 개념: Object Set Diffusion
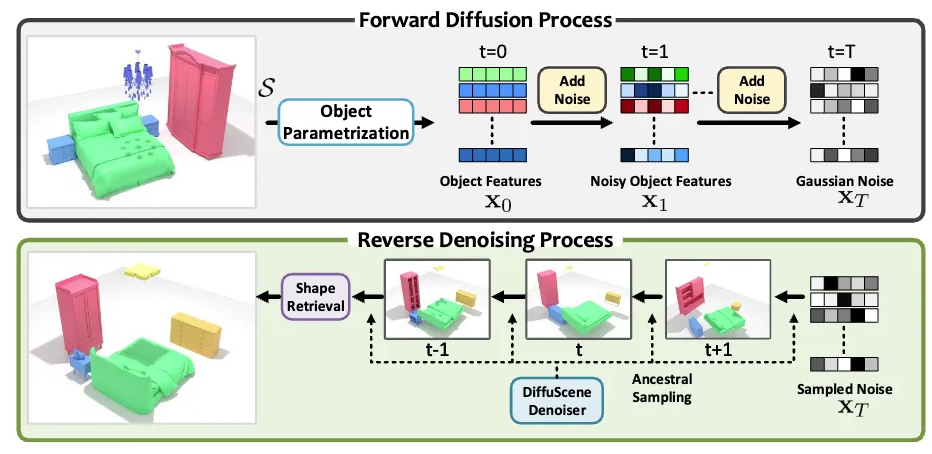
DiffuScene은 Denoising Diffusion Model(DDM)을 이용해 객체 속성을 점진적으로 개선하는 방식으로 학습합니다.
- Diffusion Process (Forward Process)
- 장면의 객체 속성에 점진적으로 가우시안 노이즈를 추가하여 흐려지게 만듭니다.
- 이 과정을 통해 모델이 노이즈가 심한 장면에서도 의미를 파악할 수 있도록 합니다.
- Generative Process (Denoising Process)
- 학습된 모델이 노이즈가 포함된 장면에서 원래 장면을 복원하도록 학습됩니다.
- 이렇게 하면 랜덤한 초기 상태에서 점차 자연스러운 3D 장면을 생성할 수 있게 됩니다.
Denoising Network
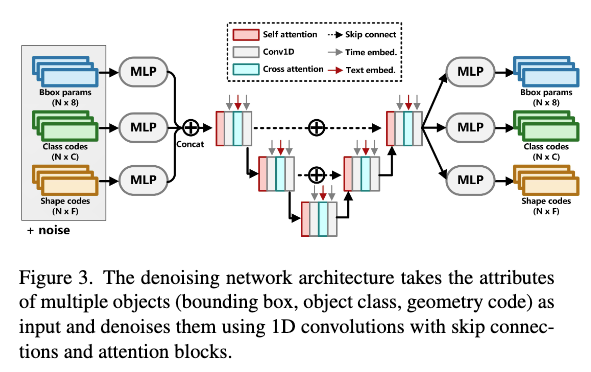
- Skip Connection이 포함된 1D 컨볼루션 신경망을 사용합니다.
- Self-Attention을 적용해 객체 간의 관계를 더 잘 이해하도록 합니다.
DiffuScene의 학습 목표 (Loss Function)
DiffuScene은 객체 배치를 학습하기 위해 두 가지 손실 함수를 사용합니다.
- $L_{sec}$: Scene Consistency Loss
생성된 객체들이 원래 데이터 분포와 유사하도록 하는 손실 함수
\[\begin{array}{l} \mathcal{L}_{\mathrm{sce}} := \mathbb{E}_{\mathrm{x_o}, \epsilon, t} \left[ \left| \epsilon - \epsilon_{\phi}({\mathbf{x}}_t, t) \right|^2 \right] \\ = \mathbb{E}_{\phi} \left[ \left| \epsilon - \epsilon_{\phi} \left( \sqrt{\bar{\alpha}}_t \mathbf{x}_0 + \sqrt{1-\bar{\alpha}}_t \epsilon, t \right) \right|^2 \right] \end{array}\]
- $L_{iou}$: Intersection-over-Union Loss
객체 간의 intersection을 이용해서 중첩을 최소화하는 Regularization Loss
\[\mathcal{L}_{\mathrm{iou}} := \sum_{t=1}^{T} 0.1 \cdot \overline{\alpha}_t \cdot \sum_{\mathrm{o}_i, \mathrm{o}_j \in \tilde{\mathbf{x}}_0^t} \mathrm{IoU}(\mathrm{o}_i, \mathrm{o}_j)\]- $\tilde{\mathbf{x}}_0^t$: 예측된 클린 scene
이러한 손실 함수를 함께 사용하면, 더 현실적이고 자연스러운 3D 장면을 생성할 수 있습니다.
Applications
Scene Completion: 불완전한 장면을 채워넣기
어떤 3D 공간이 있다고 가정해봅시다. 그런데 일부 객체가 빠져 있어 장면이 어색하게 보인다면? DiffuScene은 디퓨전 모델이 학습한 사전 지식을 이용해 빠진 객체를 자연스럽게 채워 넣을 수 있습니다. 예를 들어, 테이블과 의자 몇 개가 있는 거실에서 빠진 가구를 예측해 추가하는 식이죠. 이 과정에서 새로운 객체가 생성되며, 이를 기존 장면 에 추가하면 완전한 객체 집합 을 얻을 수 있습니다.
Scene Re-arrangement: 3D 공간 재배치
장면 속 객체들이 어수선하게 배치되어 있다면? DiffuScene은 디퓨전 모델을 활용해 장면을 더 자연스럽게 재구성할 수 있습니다. 처음에는 랜덤하게 배치된 객체들을 입력으로 받고, 이를 노이즈가 포함된 장면 으로 초기화한 뒤 점진적으로 정돈된 상태로 바꿉니다. 예를 들어, 가구들이 엉망으로 놓여 있는 방을 입력하면, DiffuScene이 적절한 위치로 가구를 이동시켜 더 깔끔하고 기능적인 배치를 제안할 수 있습니다.
Text-Conditioned Scene Synthesis: 텍스트 기반 3D 장면 생성
“소파 옆에 테이블을 놓고, 그 위에 램프를 두자” 같은 문장만으로 3D 장면을 만들 수 있다면 어떨까요? DiffuScene은 사전 훈련된 BERT 인코더를 활용해 텍스트의 의미를 파악하고, cross-attention layer를 통해 모델이 텍스트 정보를 반영하도록 유도합니다. 즉, 사용자가 원하는 객체 유형과 공간적 관계를 설명하는 문장을 입력하면, 이를 반영한 3D 장면이 자동으로 생성됩니다.
실험
DiffuScene의 학습과 평가를 위해 3D-FRONT 데이터셋을 사용했습니다. 이 데이터셋은 다음과 같은 특징을 갖고 있습니다:
- 총 6,813개의 주택과 14,629개의 방으로 구성된 대규모 합성 데이터셋
- 각 방에는 3D-FUTURE 데이터셋에서 가져온 고품질 3D 가구 객체들이 배치됨
- ATISS(Autoregressive Transformer for Indoor Scene Synthesis)와 동일한 방식으로 데이터셋을 구성하여 실험 진행
세부적으로, 침실(4,041개), 식당(900개), 거실(813개)으로 데이터를 분류하고, 각 유형별로 80%를 훈련 데이터, 20%를 테스트 데이터로 사용했습니다.
비교 대상 모델 (Baselines)
DiffuScene의 성능을 평가하기 위해 기존 연구에서 제안된 여러 모델들과 비교했습니다:
- DepthGAN: 다중 시점에서 본 3D 깊이 정보를 활용해 장면을 생성하는 GAN 기반 모델
- Sync2GAN: 3D 객체 속성을 시퀀스로 변환하여 학습하는 VAE 기반 모델
- ATISS: 3D 바운딩 박스를 하나씩 예측하는 autoregressive transformer 모델
모델 구현 및 학습 설정 (Implementation)
모델 학습에는 다음과 같은 설정을 사용했습니다:
- 배치 크기: 128
- T(타임 스텝): 100,000
- GPU: RTX 3090
- 학습률 (LR): 2e-4
- 디퓨전 모델(DDPM) 기본 설정 적용
- 노이즈 강도: 0.0001에서 0.02까지 선형 증가
추론 과정에서는 Ancestral sampling strategy를 활용하여 객체 속성을 생성하고, 이를 3D-FUTURE 데이터셋에서 가장 유사한 CAD 모델을 검색하여 최종 장면을 구성했습니다.
평가 지표 (Evaluation Metrics)
DiffuScene의 성능을 다양한 지표를 사용하여 평가했습니다:
- 기존 연구에서 사용한 메트릭
- FID: 생성된 장면의 품질 평가
- Kernel Inception Distance (KID x 0.001): 생성된 샘플과 실제 데이터 간의 분포 차이 측정
- Scene Classification Accuracy (SCA): 장면의 합리성을 평가하는 지표 (50%에 가까울수록 좋음)
- Category KL Divergence (CKL x 0.01): 생성된 장면의 객체 분포가 실제와 얼마나 유사한지 측정
- DiffuScene에서 추가로 고려한 메트릭
- Obj: 장면당 평균 객체 수
- Sym: 각 장면에서 평균 대칭 객체 쌍의 수
- Pair-wise Object Bounding Box Intersection over Union (PIoU x 0.01): 객체 간 상호작용 및 배치의 적절성을 평가
이러한 메트릭을 통해 DiffuScene이 기존 방법들보다 얼마나 현실적이고 조화로운 장면을 생성할 수 있는지 검증할 수 있었습니다.
실험 결과
Unconditional scene synthesis
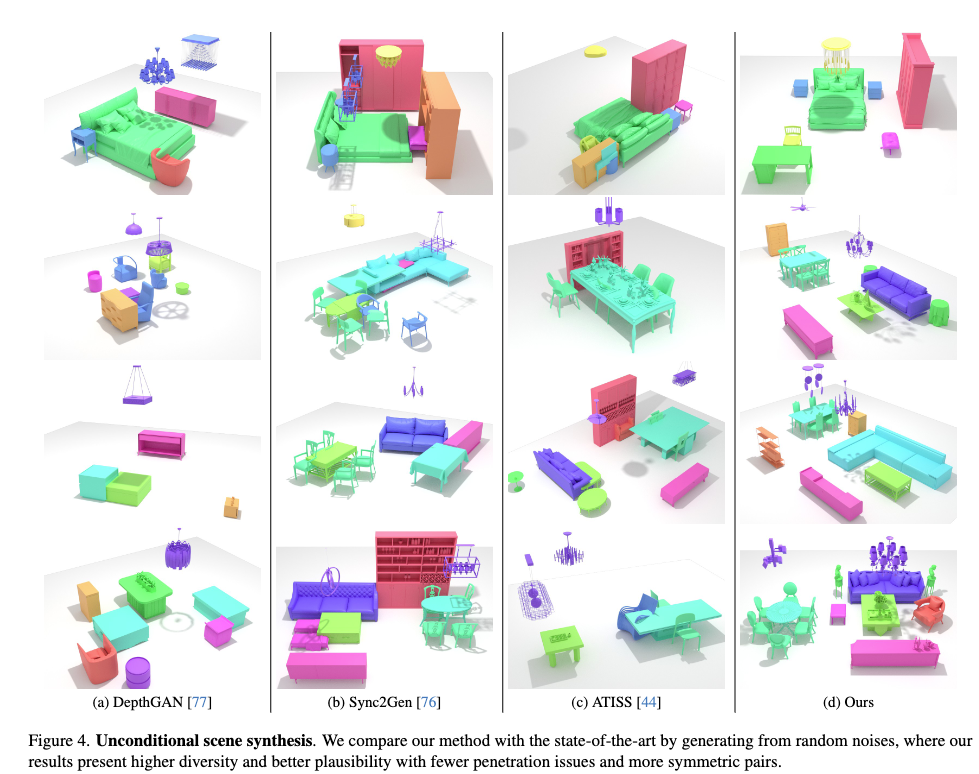
DiffuScene은 기존 방법들보다 더 자연스럽고 다양한 3D 장면을 생성할 수 있습니다. 기존 모델인 DepthGAN과 Sync2Gen은 객체들이 서로 겹치는 문제가 있었고, ATISS는 이러한 문제를 줄이긴 했지만 여전히 비현실적인 배치가 발생하는 경우가 있었습니다. 반면, DiffuScene은 디퓨전 모델을 활용해 보다 합리적이고 조화로운 배치를 생성합니다.
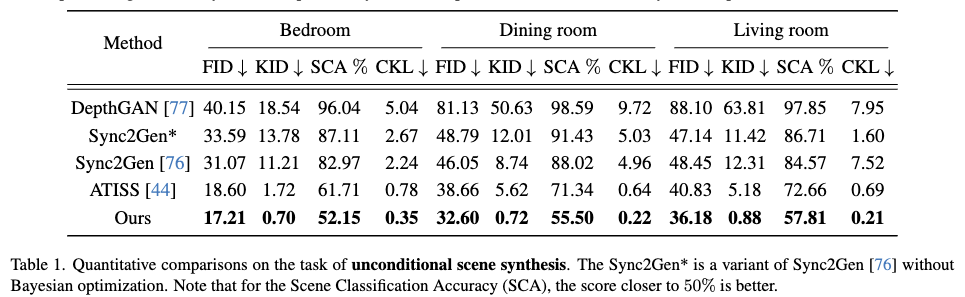
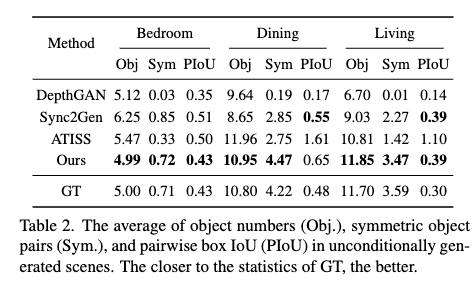
정량적인 수치에서도 DiffuScene이 IoU 손실과 기하학적 특징 확산을 적용한 모델이 더 높은 점수를 기록하며, 대칭성과 장면의 자연스러움을 개선하는 데 효과적인 것을 볼 수 있습니다.
Ablation study에 관한 실험 결과는 아래와 같습니다.
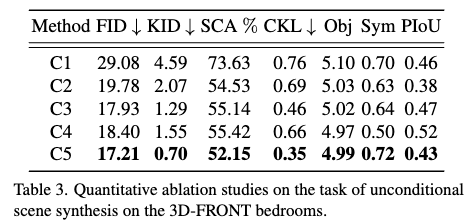
- UNet-1D Attention이 미치는 효과 (C1 vs C5)
- Multiple prediction head가 미치는 효과 (C2 vs C5)
- 객체 속성에 대해 세 가지 다른 인코딩 및 예측 헤드를 사용
- IoU loss의 효과 (C3 vs C5)
- Geometry feature diffusion의 효과 (C4 vs C5)
- Shape diffusion이 있을 때와 없을 때의 차이 → 대칭성이 두드러짐
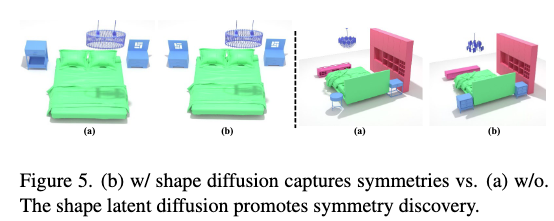
즉 각 요소의 기능을 아래로 정리할 수 있습니다!
- UNet-1D + Attention 기반 디노이저: 일반적인 트랜스포머 기반 디노이저보다 성능이 뛰어나며, 보다 안정적인 장면 생성을 돕습니다.
- 다중 예측 헤드(Multiple Prediction Heads): 객체의 위치, 클래스, 기하학적 특징을 개별적으로 예측하여 한 가지 속성에 편향되지 않도록 합니다.
- IoU(Intersection over Union) 손실 함수: 객체 간 겹침을 줄이고 대칭적인 배치를 유도하여 더 정돈된 장면을 생성할 수 있습니다.
- 기하학적 특징(Geometry Feature) 확산: 객체들의 공간적 관계를 더 잘 반영하여 대칭적이고 의미 있는 배치를 유도합니다.
응용 실험
DiffuScene의 성능을 검증하기 위해 다양한 실험을 진행했습니다.
- Scene Completion: 기존의 ATISS보다 더 다양하고 사실적인 장면을 완성할 수 있으며, 객체 간의 교차를 줄이고 대칭적인 배치를 더 잘 반영합니다.
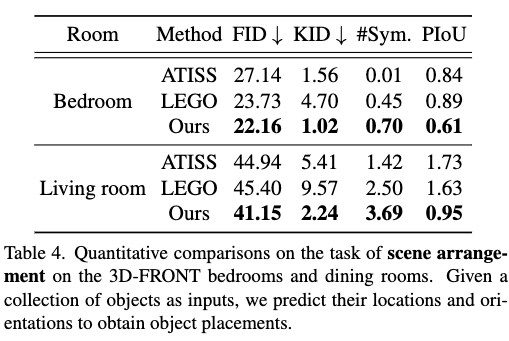
 더 다양한 장면을 만들 수 있음
더 다양한 장면을 만들 수 있음
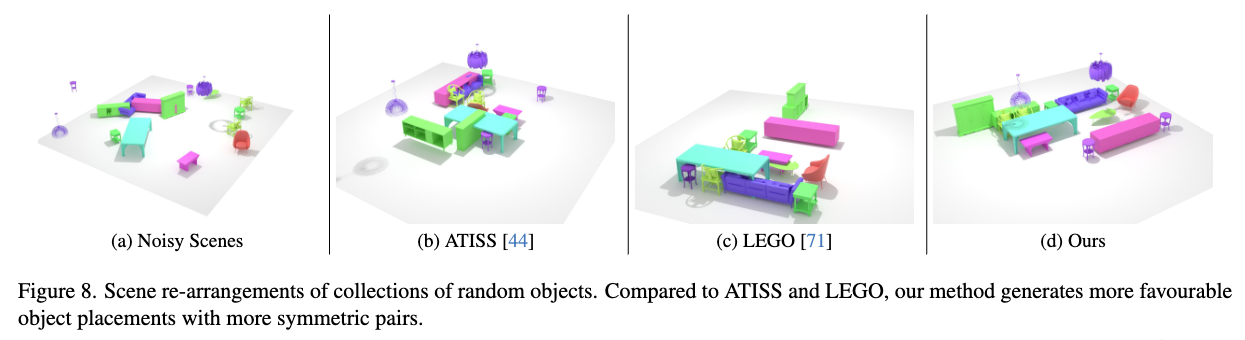
Scene Re-arrangement: 기존 모델과 비교했을 때 더 직관적이고 합리적인 가구 배치를 생성할 수 있습니다.
Text-Conditioned Scene Synthesis: 사용자 실험 결과, 62%의 참가자가 DiffuScene이 더 현실적이라고 평가했으며, 55%가 입력 텍스트와의 일치도가 더 높다고 응답했습니다.
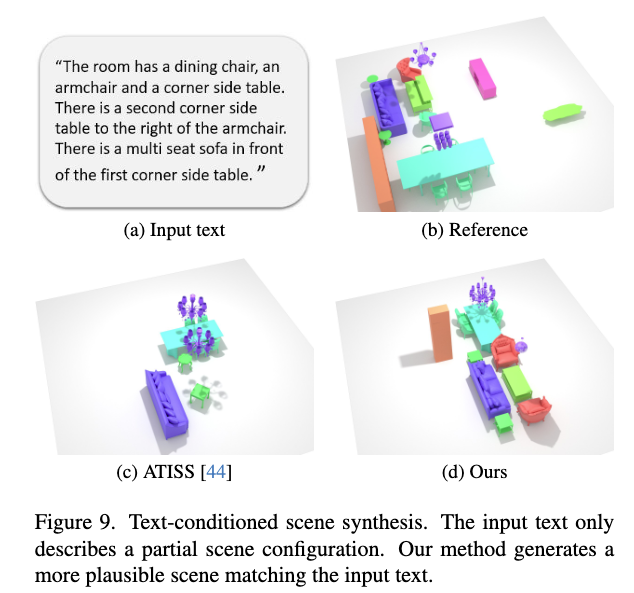
Limitations
저자들은 DiffuScene이 다음가 같은 한계점을 가지고 있다고 합니다.
- 형태 검색(Shape Retrieval)의 한계: 생성된 객체가 원하는 스타일과 다를 수 있음.
- 객체의 텍스처 한정: 현재는 3D CAD 모델에서 텍스처를 가져오기 때문에, 더 풍부한 표현을 위해 텍스처 모델링을 추가할 필요가 있음.
- 단일 방(Scene) 중심: 현재는 하나의 방 단위로만 학습되며, 여러 개의 방을 포함하는 대규모 공간은 생성할 수 없음.
- 3D 라벨된 데이터 필요: 2D 데이터를 활용해 선행 학습하는 방법도 고려할 수 있음.
DiffuScene은 Denoising Diffusion Model을 활용한 3D 실내 장면 생성 모델로, 기존 방식보다 더 자연스럽고 일관성 있는 공간을 디자인할 수 있습니다. 특히 다음과 같은 강점을 가지고 있습니다:
- 객체 간의 관계를 학습하여 더욱 현실적인 배치 가능
- 주어진 부분 장면을 완성하거나 재배치 가능
- 텍스트를 기반으로 3D 장면을 생성 가능
CVPR 2024 논문 임에도 불구하고 사용된 방법은 굉장히 간단해 보입니다. 23년 3월에 아카이브에 올라온 논문으로 디퓨전을 이용한 실내 장면 합성 분야에 초기 논문입니다. 기술이 발전하면 인테리어 디자인, 가상 현실(VR), 게임 개발 등 다양한 분야에서 활용될 가능성이 커질 것입니다. 앞으로의 연구가 더욱 기대됩니다! 😃