[논문리뷰] Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation

오늘 소개 드릴 논문은 알리바바에서 발표한 Animate Anyone입니다. 현재 공식 코드는 레포만 만들어져 있는데 언제인지는 모르지만 코드는 공개할 예정이라고 합니다! 공식 코드는 아니지만 다른 분께서 구현해 놓은 코드가 있으니 참고하시길 바랍니다. 그리고 결과 영상 등은 해당 페이지에서 보실 수 있습니다.
구체적인 내용 소개에 앞서 해당 모델의 결과물 영상을 보여드리겠습니다.
위 영상에서 볼 수 있듯이 이 모델은 이미지가 주어지고 그 이미지에 있는 인물에게 움직임을 주고 싶은 포즈 시퀀스를 입력으로 받아서 이미지에 있는 인물이 해당 포즈 시퀀스를 가지고 움직이는 것 같은 영상을 만들어줍니다! (입력: 움직임을 주려는 대상이 포함된 이미지, 포즈 시퀀스 / 출력: 이미지의 대상이 포즈 시퀀스에 맞게 움직이는 영상)
핵심 요약
- 대상이 포함된 이미지, 포즈 시퀀스를 입력으로 받아 대상이 포즈 시퀀스에 맞게 움직이는 영상을 만들어주는 모델
- 네트워크 구성: ReferenceNet, Pose Guider, Temporal Modeling
- ReferenceNet: 캐릭터의 외관특징 보존, 입력된 이미지의 공간적 세부 정보를 캡처하는 네트워크
- Pose Guider: 캐릭터의 동작을 안내하는 역할, 포즈 정보의 다양한 특징을 추출하고 캐릭터 이미지에 반영
- Temporal Modeling: 연속된 이미지 프레인 간의 부드러운 전환을 보장하기 위한 접근 방식
1. Introduction
캐릭터 애니메이션은 원본 캐릭터 이미지에서 사실적인 비디오를 생성하는 작업으로, GAN을 시작으로 많은 연구가 진행되었습니다. 그러나 생성된 이미지 또는 비디오는 지역적 왜곡, 흐릿한 세부 사항, 의미적 불일치, 시간적 불안정성과 같은 문제로 인해 널리 사용되기에는 어려움이 있었습니다.
최근에는 diffusion 모델의 우수성에 따라 이미지-비디오 변환 작업에 diffusion 모델을 활용하려는 연구들이 늘어나고 있습니다. 예를 들어 DreamPose(23.04), DisCO(23.07)등이 diffusion 모델을 활용한 방법입니다. DreamPose는 stable diffusion을 확장하여 패션 이미지에서 비디오 합성에 초점을 맞추었습니다. 이 모델은 CLIP과 VAE 기능을 통합한 어댑터 모듈을 제안했습니다. 그러나 일관된 결과를 얻기 위해 입력 샘플에 대한 추가적인 파인튜닝이 필요하며 운용 효율이 떨어집니다.DisCO는 stable diffusion을 확장하여 인간 댄스 생성을 진행했습니다. 이를 위해 CLIP과 ControlNet을 활용한 통합 모델을 구축했습니다. 그러나 캐릭터 세부 사항을 보존하는 데 어려움을 겪었고 프레임 간의 jittering 문제가 존재합니다.
텍스트-이미지 생성 및 비디오 생성에서 시각적 품질과 다양성 측면에서 큰 진전이 있었지만, 복잡한 세부 사항을 잘 살리는 것이 어려우며 정확도 측면에서도 부정확한 부분이 있습니다. 더욱이, 실질적인 캐릭터 움직임을 다룰 때 안정적이고 연속적인 비디오를 만들어내는 것이 어렵습니다. 현재로서는 일반성과 일관성을 동시에 만족하는 캐릭터 애니메이션 방법을 찾을 수 없었고, 따라서 본 논문에서 “Animate Anyone” 방법을 제안합니다.
Animate Anyone 모델은 다음과 같은 구조로 구성되어 있습니다.
- ReferenceNet: 캐릭터의 외관특징 보존, 입력된 이미지의 공간적 세부 정보를 캡처하는 네트워크
- Pose Guider: 캐릭터의 동작을 안내하는 역할, 포즈 정보의 다양한 특징을 추출하고 캐릭터 이미지에 반영
- Temporal Modeling: 연속된 이미지 프레인 간의 부드러운 전환을 보장하기 위한 접근 방식
제안한 모델은 다음과 같은 장점을 가집니다.
- 캐릭터 외관의 공간 및 시간적 일관성을 효과적으로 유지합니다.
- 시간적으로 떨림 및 깜빡임과 같은 문제가 없는 높은 신뢰성의 비디오를 생성합니다.
- 어떤 캐릭터 이미지에도 애니메이션 비디오를 생성할 수 있습니다.
본 논문에서 제안한 모델은 벤치마크 결과에서도 우수한 결과를 보였습니다.
2. Related Works
디퓨전 기반 이미지 생성 모델로는 LDM(Latent Diffusion Model)이 있고, 비디오 생성 모델로는 Video LDM, AnimateDiff등과 같은 모델이 있습니다. 본 논문은 AnimateDiff에서 고안된 temporal 모델링에 영감을 많이 받았다고 합니다.
3. Methods
3-1. Preliminary: Stable Diffusion
Animate Anyone은 stable diffusion을 기반으로 한 모델이기에 stable diffusion에 대해 설명하겠습니다. Stable Diffusion은 LDM(Latent Diffusion Model)을 발전시킨 모델로 LDM은 아래와 같은 구조를 가집니다. Latent라는 단어가 들어간 것으로 유추할 수 있듯이 픽셀 공간에서 이뤄지던 디퓨전 과정을 VAE를 통해 latent 공간으로 변경하여 컴퓨팅 측면에서 더 효율적으로 denoising이 이뤄지게 합니다.

3.2 네트워크 구조
전체 네트워크 구조는 아래와 같이 구성되어 있습니다.
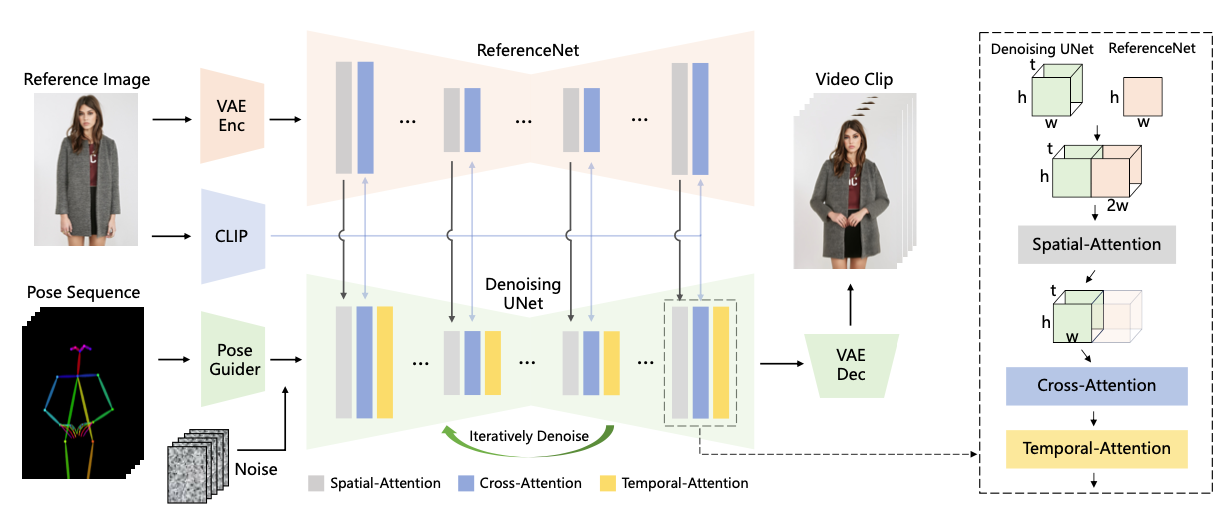
전체 네트워큰 아래의 3 개의 중요 요소들이 통합된 형태로 구성되어 있습니다.
- ReferenceNet: 캐릭터의 외관특징 보존, 입력된 이미지의 공간적 세부 정보를 캡처하는 네트워크
- Pose Guider: 캐릭터의 동작을 안내하는 역할, 포즈 정보의 다양한 특징을 추출하고 캐릭터 이미지에 반영
- Temporal Modeling: 연속된 이미지 프레인 간의 부드러운 전환을 보장하기 위한 접근 방식
ReferenceNet
ReferenceNet은 캐릭터의 외관특징 보존, 입력된 이미지의 공간적 세부 정보를 캡처하는 네트워크입니다. 해당 요소는 CLIP 이미지 인코더가 디테일 일관성 측면에서 부족하기 때문에 고안되었습니다. CLIP 이미지 인코더는 224x224의 낮은 해상도 이미지들로 구성되어 중요한 세부 정보의 손실이 있을 수 있고, CLIP은 텍스트에 더 적합하게 훈련되어 high-level 특성 매칭에 중점을 두고 있으며, 이에 따라 디테일 특성 측면에서 부족함이 있다고 합니다. 따라서 별도의 ReferenceNet으르 통해 입력된 이미지의 디테일을 더 잘 캡쳐하도록 하였습니다.
ReferenceNet은 stable diffusion처럼 UNet의 구조로 이루어지게 됩니다. 그리고 기존 사전학습된 stable diffusion의 가중치로 초기화 됩니다. ReferenceNet에서 나온 feature는 이후 denoising UNet에 들어가게 됩니다.
ReferenceNet의 feature와 denoisingUNet에 feature가 통합되는 과정은 아래의 그림으로 나타낼 수 있습니다.
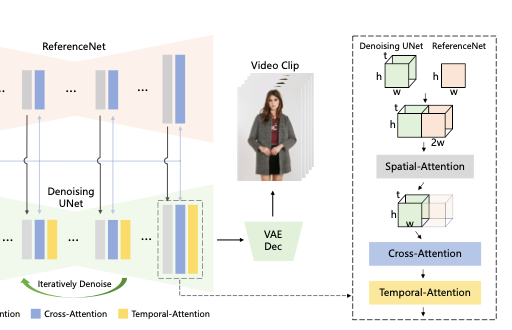
ReferenceNet에는 입력 이미지를 t번 복사해서 (Denoising UNet에 입력으로 들어가는 포즈 시퀀스랑은 다르게 시간축에 대한 차원이 없으므로) 차원을 맞춰준 후, w축에 대해 합쳐줍니다. 결과적으로 Denoising UNet과 ReferenceNet에 feature가 합쳐져 (t,h,2w,c) feature가 만들어집니다. 이후 Spatial-Attention을 수행하고, feature map의 반을 결과로 뽑습니다. 다음으로는 Cross-Attention과 Temporal-Attention을 거쳐 최종 결과가 만들어집니다. 참고로 Cross-Attention을 할 때는 CLIP 이미지 인코더를 도입하여 reference 이미지의 의미적 특성을 제공함으로써 전체 네트워크의 초기값 설정을 빠르게 할 수 있게 합니다.
ReferenceNet의 디자인은 다음과 같은 장점을 가집니다.
- 사전 학습된 이미지 특성 모델 SD를 사용함으로써 초기값을 잘 정의할 수 있다.
- Denoising UNet과 ReferenceNet의 초기값이 공유되고 동일한 네트워크 구조를 가지므로, Denoising UNet은 ReferenceNet feature 중 선택적으로 학습할 수 있다.
- 타 diffusion 기반 video generation에서는 모든 video frame에 대해 denoising을 진행
다른 디퓨전 기반 비디오 생성 방법에서는 모든 비디오 프레임에 대해 denoising을 진행하지만, ReferenceNet은 feature를 추출할 때 한 번만 필요하며, 이로 인해 추론 단계에서 계산량이 증가하지 않는다는 장점이 있습니다.
Pose Guider
Pose Guider는 캐릭터의 동작을 안내하는 역할, 포즈 정보의 다양한 특징을 추출하고 캐릭터 이미지에 반영하는 역할을 합니다. ControlNet을 이용해서 조건을 넣어줄 수 있지만 그러기 위해서는 추가적인 파인튜닝이 필요합니다. 본 논문에서는 추가적인 계산량 증가를 막기 위해 lightweight Pose Guider를 도입했습니다. 아주 간단하게 네 개의 컨볼루션 레이어를 사용했습니다. (4x4 커널과 2x2 스트라이드, 각각은 16, 32, 64, 128 채널 사용) 가우시안 가중치 초기화 방법을 이용했고, 최종 프로젝션 레이어에는 제로 컨볼루션을 도입했습니다.
Temporal Layer
Temporal Layer는 연속된 이미지 프레인 간의 부드러운 전환을 보장하기 위한 레이어입니다. 기존에도 많은 모델들이 T2I 모델에 temporal layer를 도입함으로써 프레임 간의 시간적인 종속성을 갖도록 했습니다.
본 논문에서는 U-Net 내의 Res-Trans 블록 내에 있는 Spatial-Attention과 Cross-Attention을 수행한 후에 Temporal-Attnetion을 수행합니다.
과정은 다음과 같습니다.
- Cross-Attention을 거쳐서 나온 feature를 reshape합니다.
- $x \in \mathcal{R}^{b \times t \times h \times w \times c }$ → $x \in \mathcal{R}^{(b \times h \times w) \times t \times c }$
- Temporal attention을 수행한 후에 residual connection을 적용합니다.
이 레이어를 통해 세부 사항에 대해 시간적인 부드러움과 연속성이 향상되게 됩니다.
3.3 Training Strategy
모델 훈련은 두 단계로 이루어지게 됩니다. 첫 번째는 temporal layer를 제외하고 훈련을 하고, 두 번째는 temporal layer만 훈련하는 과정으로 이뤄집니다.
첫 번째 훈련 단계는 temporal layer를 제외하여 1개의 프레임으로만 이뤄진 노이즈를 입력으로 받습니다. Reference 이미지는 전체 비디오 클립에서 랜덤으로 선택되고, 초기 가중치는 사전학습된 stable diffusion의 가중치로 초기화 됩니다.
- 첫 번째 단계
- Temporal layer 제외
- 1개의 프레임으로만 이뤄진 노이즈를 입력으로 받음
- Reference 이미지는 전체 비디오 클립에서 랜덤으로 선택 됨
- 초기 가중치는 사전학습된 stable diffusion의 가중치로 초기화 됨
- Pose Guider는 마지막 projection layer를 제외한 모든 layer gaussian weight 초기화
- VAE Encoder, Decoder, CLIP image encoder 는 그대로
- 두 번째 단계
- Temporal layer만 훈련
- temporal layer 초기값 : AnimateDiff pretrained weight
- 입력 : 24frame video clip
4. Experiments
본 논문의 실험 결과에 대해 설명 드리겠습니다.
4.1 Implementations
실험 설정은 아래와 같습니다.
- 학습 데이터 : 5K 캐릭터 비디오 클립 영상 (2~10초 길이, 인터넷에서 다운로드 받은 영상)
- 영상에 있는 캐릭터의 포즈 시퀀스를 추출하기 위해 https://github.com/IDEA-Research/DWPose를 이용하였다.
- GPU : 4 NVIDIA A100 GPUs
- 첫 번째 훈련 단계
- Temporal layer를 제외한 훈련
- 비디오 프레임 샘플링, 리사이즈, center-crop을 적용하여 768x768 해상도로 만듦
- 배치 사이즈: 64
- 트레이닝 스텝 수: 30,000
- 두 번째 훈련 단계
- Temporal layer만 훈련
- 24 프레임의 비디오 시퀀스
- 배치 사이즈: 4
- Learning rates : 1e-5
- 추론 단계 :
- Reference image의 캐릭터 스켈레톤 길이와 비슷해지도록 포즈 스켈레톤의 길이를 리스케일
- DDIM 샘플러 이용 (20 디노이징 스텝)
- 긴 영상 생성을 위해 temporal aggregation method 채택
- 평가: 2개의 벤치마크 데이터셋 사용(UBC fashion video dataset, Tik-Tok dataset)
4.2 Qualitative Results
 맨 왼쪽 이미지: 레퍼런스 이미지
맨 왼쪽 이미지: 레퍼런스 이미지
전신이 나오는 캐릭터, 절반 길이의 초상화, 카툰 캐릭터, 인간형 캐릭터에 대해서 애니메이션을 생성하게 되었고, 결과 레퍼런스 이미지와 유사한 시간적 일관성(temporal consistency)을 보이는 사실적인 결과가 생성되었다고 합니다.
4.3 Comparisons
다른 이미지 애니메이션 방법들과 비교하기 위해 패션 비디오 합성(fashion video synthesis)과 휴먼 댄스 생성(human dance generation) 태스크에 대해 SSIM, PSNR, LIPS 지표를 이용해서 비교하였습니다. 영상 레벨 지표로는 FVD 지표를 사용해서 평가했습니다.
Fashion Video Synthesis
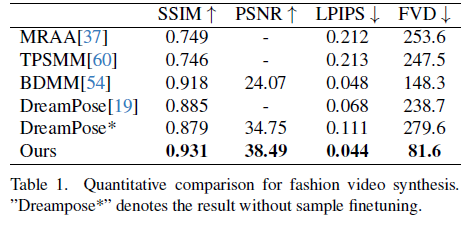

수치상으로도 제안한 논문의 모델의 성능이 좋았고 정성적으로도 본 논문의 방법이 제일 좋았다고 합니다. DreamPose, BDMM은 옷의 일관성을 잃어버리는 문제가 있고, 색과 섬세한 구조적 요소에 대한 에러가 발생하였지만 본 논문이 제안한 모델은 옷의 세부 내용까지 일관적으로 보존되었다고 합니다.
Human Dance Generation


휴먼 댄스 생성에 대해서도 본 논문의 모델이 수치상으로도 성능이 좋았고 정성적으로도 좋았다고 합니다. Disco에서는 인물의 foreground 마스크를 위해 SAM(Segment Anything Model)을 사용해야만 했는데 본 논문의 방법에서는 SAM이 없이도 대상 모션을 통해 foreground와 background 구분이 가능합니다. 또한, 복잡한 댄스 시퀀스에서도 시각적으로 연속적인 모션을 보여줬습니다.
General Image-to-Video Methods

이미지를 비디오로 바꾸는 태스크에 대해서는 AnimateDiff와 Gen-2와 성능을 비교했습니다. 레퍼런스 이미지에 대한 외관 신뢰도만 비교하였고, 본 논문의 방법은 다른 모델 대비 긴 시간동안 외관 일관성(appearance consistency)를 유지했습니다.
4.4 Ablation study
ReferenceNet 디자인에 대한 효과성 증명을 위한 ablation study 부분입니다.


CLIP 이미지 인코더만 사용했을 때, ControlNet만 사용했을 때, CLIP과 ControlNet을 다 사용했을 때, 그리고 제안한 모델 구조에 대해 성능 테스트를 했습니다. 결과적으로 ReferenceNet를 사용하는 것이 모든 방법 대비 가장 좋았습니다.
5. Limitations
한편 저자가 말하는 본 논문 모델의 한계점은 아래와 같습니다.
- 손의 안정적인 움직임을 보이는 것에 어려움을 보였다고 합니다. 왜곡과 모션 블러등이 발생했다고 합니다.
- 제공하는 이미지는 한 측면만 보이기 때문에 보이지 않은 부분에 대해서는 불안정한 문제가 있습니다.
- DDPM을 활용했기 때문에 디퓨전이 아닌 모델 대비 운영 효율성이 낮습니다.