[논문리뷰] LayoutGPT: Compositional Visual Planning and Generation with Large Language Models (NeurIPS 2023)
오늘 소개할 논문은 NeurlPS 2023에 발표되었던 LayoutGPT라는 새로운 논문에 관한 것입니다. LayoutGPT는 대형 언어 모델(LLM)이 단순히 텍스트를 이해하는 데 그치지 않고, 시각적 레이아웃까지도 생성할 수 있음을 보여주는 매우 흥미로운 시도입니다. 특히, LayoutGPT는 텍스트 조건을 바탕으로 시각적 플래닝을 수행하고, 이를 이미지 생성 모델과 협업해 높은 품질의 이미지를 생성합니다. 연구 결과에 따르면, LayoutGPT를 통해 생성된 이미지는 기존 텍스트-이미지 생성 모델보다 20-40% 더 우수한 성능을 보였고, 3D 실내 장면 합성에서도 지도학습 방식과 유사한 성과를 냈다고 합니다. 프로젝트 페이지는 이곳이며 코드는 여기에 공개되었습니다!
아래 그림은 LayoutGPT가 할 수 있는 태스크에 대한 그림입니다. 아래와 같이 LMM을 이용해서 2D 이미지 생성을 위한 레이아웃을 만들고, 3D 공간에서도 공간에 맞는 레이아웃을 생성하여 실내 장면 합성이 가능한 것을 볼 수 있습니다. 기존 베이스라인인 ATISS보다 가구가 바운더리를 벗어나거나 가구들이 겹치는 현상들이 완화되었다고 합니다.
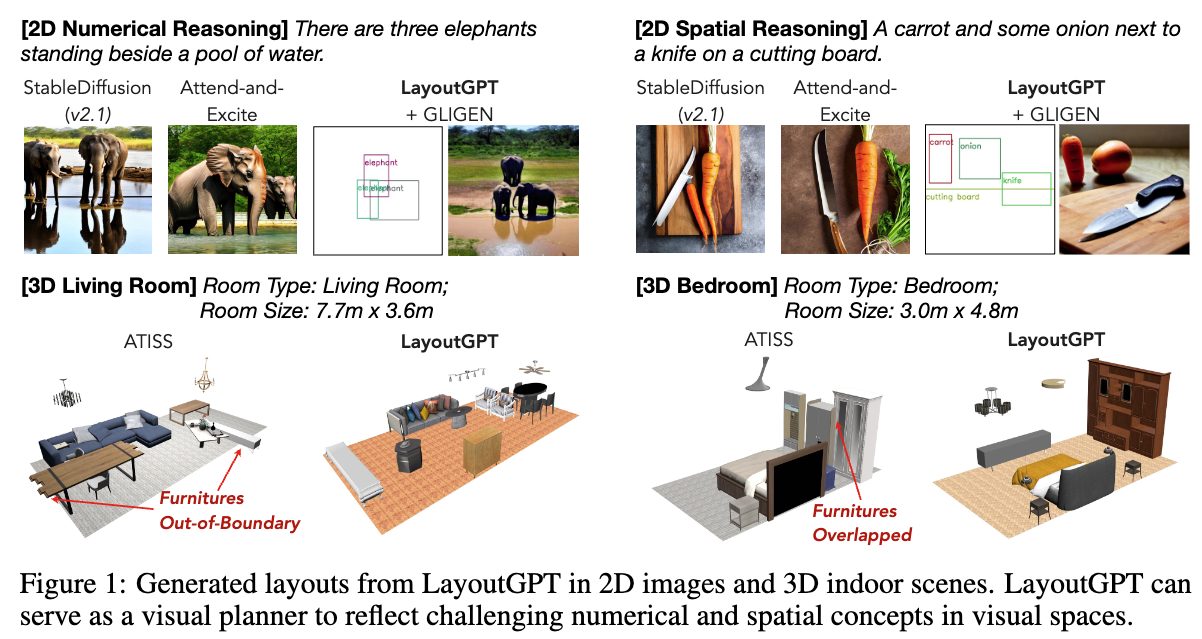
LayoutGPT의 동작 원리
LayoutGPT의 전체 프로세스에 대한 그림은 아래와 같습니다. 여기서 실선은 이미지를 합성할 때의 플로우고 점선은 3D 실내 장면은 합성할 때의 플로우입니다. Input prompt를 통해 LLM에게 쿼리를 날려 레이아웃에 대한 정보를 css 형태로 받고, 생성된 레이아웃을 통해 이미지 생성의 경우는 layout-to-image model로 이미지를 생성합니다. Input prompt 이전에 들어가는 플로우는 LLM이 결과를 더 잘 출력할 수 있도록 예제를 생성하는 플로우라고 이해하시면 됩니다. 각각에 대한 자세한 설명은 아래에서 더 이어가겠습니다.
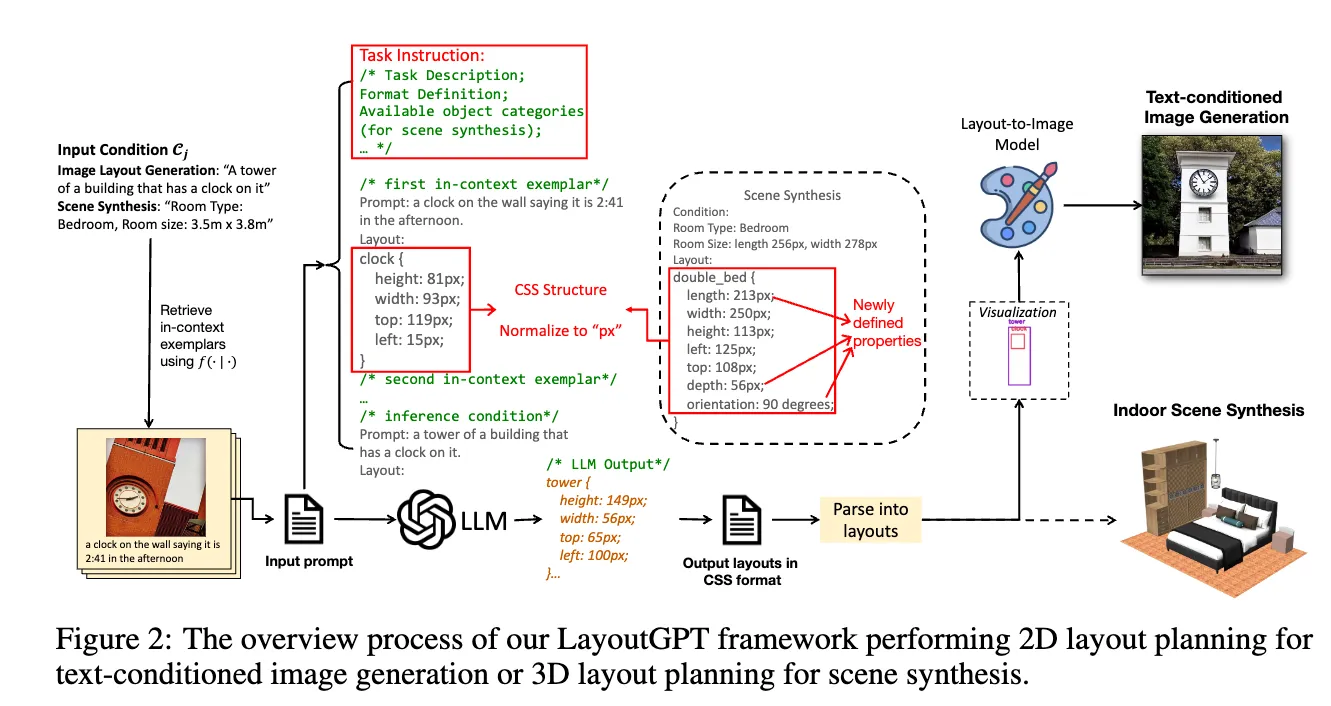
LayoutGPT의 핵심은 주어진 조건(C)에서 다수의 객체 튜플로 구성된 레이아웃 집합(𝒪)을 생성하는 것입니다.
\[\cal{O}=\{\mathbf{o}_j|j=1,2,...,n\}\]- $\mathbf{o}_j$: j번째 물체의 2D나 3D 바운딩박스 정보
여기서 객체는 2D 혹은 3D 바운딩 박스로 표현되며, 이미지 생성과 3D 장면 생성에서 각각 다른 속성을 가집니다. 이미지 플래닝에서는 C는 텍스트 프롬프트가 되고, $\mathbf{o}_j$는 카테고리 $c_j$, 바운딩 박스의 위치인 $\mathbf{t}_j$, 바운딩 박스의 사이즈인 $\mathbf{s}_j$로 구성되고, ($\mathbf{o}_j=(c_j, \mathbf{t}_j, \mathbf{s}_j)$) 3D 장면 생성에서는 C는 룸 타입과 룸 사이즈가 되고, $\mathbf{o}_j$는 카테고리 $c_j$, 위치 $\mathbf{t}_j$, 사이즈 $\mathbf{s}_j$, orientation인 $r_j$로 구성됩니다. ($\mathbf{o}_j=(c_j, \mathbf{t}_j, \mathbf{s}_j, \mathbf{r}_j)$).
LayoutGPT Prompt Construction
LayoutGPT는 다음과 같은 주요 구성 요소를 통해 작업을 수행합니다:
- Task Instructions: 작업 목표 및 요구 사항을 정의하고, 생성되는 레이아웃의 속성에 대한 규격을 명시합니다.
- CSS Structures: 레이아웃을 CSS 형식으로 구조화하여 모델이 각 요소의 스타일을 쉽게 이해하고 생성할 수 있도록 합니다.
- Normalization: 입력 값들을 표준화하여 모델이 다양한 크기나 비율의 레이아웃을 효과적으로 처리할 수 있도록 합니다.
1. Task Instructions
- 목표: 주어진 입력을 바탕으로 웹 페이지 레이아웃을 자동으로 생성하는 모델을 훈련시키는 것. 이 모델은 CSS 형식을 이용해 각 요소의 스타일을 정의하며, 각 레이아웃 요소는 적절한 카테고리와 속성으로 명확히 구분됩니다. 이를 통해 사용자 요구사항에 맞는 스타일링을 자동화할 수 있습니다.
- 형식 정의:
- Selector: CSS 스타일에서 사용되는 각 요소를 식별할 수 있는 카테고리 이름 (예:
header,footer,main,section등) - 속성: 요소에 대해 지정할 CSS 스타일 속성 (예:
width,height,margin,padding,color,background-color,font-size등) - 단위: CSS 속성의 값은 주로 픽셀(px) 단위로 제공됩니다. 값은 항상 최대 256px로 리스케일됩니다.
- Selector: CSS 스타일에서 사용되는 각 요소를 식별할 수 있는 카테고리 이름 (예:
아래와 같이 task instruction을 줄 수 있습니다.

2. CSS Structures
- 기존 방식: 이전의 autoregressive 레이아웃 생성 모델은 레이아웃 요소를 시퀀스로 모델링했지만, 각 값의 의미가 명확하지 않아서 모델이 특정 스타일 속성을 올바르게 이해하는 데 어려움이 있었습니다. 예를 들어,
c_1, x_1, y_1, w_1, h_1, c_2, x_2, ...와 같은 형태는 각 값이 무엇을 의미하는지 직관적으로 알기 어렵습니다. - CSS 포맷 변환: 본 논문에서는 레이아웃이 CSS 형식과 유사하다는 사실을 발견한 후, 기존의 시퀀스를 CSS 스타일로 변경하여 각 속성에 대한 명확한 의미를 부여했습니다.
- 예를 들어,
c_j를 CSS의 선택자로 사용하고, 나머지 값들을 해당 선택자의 CSS 속성으로 매핑합니다. 이렇게 하면 각 스타일이 명확하게 정의되며, 모델이 CSS 형식을 더 잘 이해할 수 있게 됩니다.
- 예를 들어,
- LLM 학습: 대형 언어 모델(LLM)은 코드 조각을 통해 학습되기 때문에, CSS 포맷이 더 큰 잠재력을 가지고 있으며, 이를 통해 모델이 생성하는 레이아웃이 더 정확하고 효율적으로 될 수 있습니다.
3. Task Instructions & Normalization
- 작업 목표: 입력된 레이아웃 데이터를 바탕으로 CSS 형식의 스타일을 자동 생성하는 작업입니다. 생성된 스타일은 페이지 요소를 적절하게 배치하고, 디자인을 최적화하는 데 사용됩니다.
- 표준 형식 정의: CSS의 길이 단위는 일반적으로
px(픽셀)입니다. 따라서 모든 속성 값은 고정된 scalar 기준을 사용하여 최대 256px로 리스케일됩니다. 예를 들어, 원래의 크기가 512px인 속성은 256px로 리스케일하여 모델에 제공됩니다. 이를 통해 생성된 레이아웃의 일관성을 유지하고, 크기 조정이 용이해집니다. - 정규화: 모든 값은
256px를 최대 크기로 설정하여 모델의 출력이 일관되게 만들어집니다. 예를 들어, 512px 크기의 요소가 있을 경우, 이를 256px로 정규화하여 모델에 입력으로 사용합니다. 이렇게 정규화된 값은 레이아웃의 크기 비율을 유지하며, 더 넓은 범위에서 스타일링을 최적화하는 데 도움이 됩니다.
이밖에도 LayoutGPT에서는 LMM이 해당 태스크를 잘 수행할 수 있도록 예제를 넣어줍니다. 이를 In-Context Exemplars Selection이라고 합니다.
In-Context Exemplars Selection
이 방법에서는 테스트 조건에 대해 가장 유사한 예시들을 선택하여 모델에게 제공함으로써, 모델이 과거의 경험을 바탕으로 더 정확한 예측을 할 수 있도록 돕습니다. 이 과정은 주로 검색 기반 예시 선택을 통해 이루어지며, 이를 통해 다양한 작업에서 성능을 개선할 수 있습니다.
2D 텍스트 조건 이미지 레이아웃 생성
먼저, 2D 텍스트 조건 이미지 레이아웃 생성 작업을 예로 들어보겠습니다. 이 작업에서는 텍스트 조건이 주어지면 해당 텍스트를 기반으로 이미지 레이아웃을 생성해야 합니다. 이를 위해, CLIP 모델을 사용하여 텍스트 특징과 이미지 특징을 추출하고, 이들 간의 코사인 유사도를 계산합니다. 코사인 유사도는 두 벡터가 얼마나 비슷한지를 측정하는 지표로, 두 특징 벡터 간의 각도를 기반으로 유사도를 산출합니다.
\[\text{Cosine Similarity}(C_k, C_j) = \frac{\mathbf{f}_{C_k} \cdot \mathbf{f}_{C_j}}{\|\mathbf{f}_{C_k}\| \|\mathbf{f}_{C_j}\|}\]3D 장면 합성
다음은 3D 장면 합성 작업에 대한 설명입니다. 3D 장면 합성에서는 각 방의 길이와 너비정보를 사용하여, 서로 다른 조건 간의 유사도를 계산합니다. 이때 두 조건 간의 거리는 다음과 같은 방식으로 측정됩니다.
\[f(C_k, C_j) = \sqrt{(r_{lk} - r_{lj})^2 + (r_{wk} - r_{wj})^2}\]여기서 $r_{lk}$와 $r_{lj}$는 각각 조건으로 주어진 $C_k$와 $C_j$의 방 길이이고, $ r_{wk}$와 $r_{wj}$는 방의 너비입니다.
위의 거리 측정을 통해 가장 적합한 지원 예시들을 선택하며, 최소 거리를 가진 상위 k개의 예시를 선택합니다. 그런 후 이 예시들을 CSS 구조에 맞게 구성하여 GPT-3.5/4 모델에 제공합니다. 예시는 역순으로 제공되며, 가장 유사한 예시는 마지막에 제공됩니다.
Results
텍스트를 조건으로 한 이미지 생성 태스크에 대한 결과는 아래와 같습니다. 정량적인 수치에서 모두 좋은 수치를 보였으며 dense layout planning과 text-based inpainting에서도 좋은 결과를 보여줬습니다.

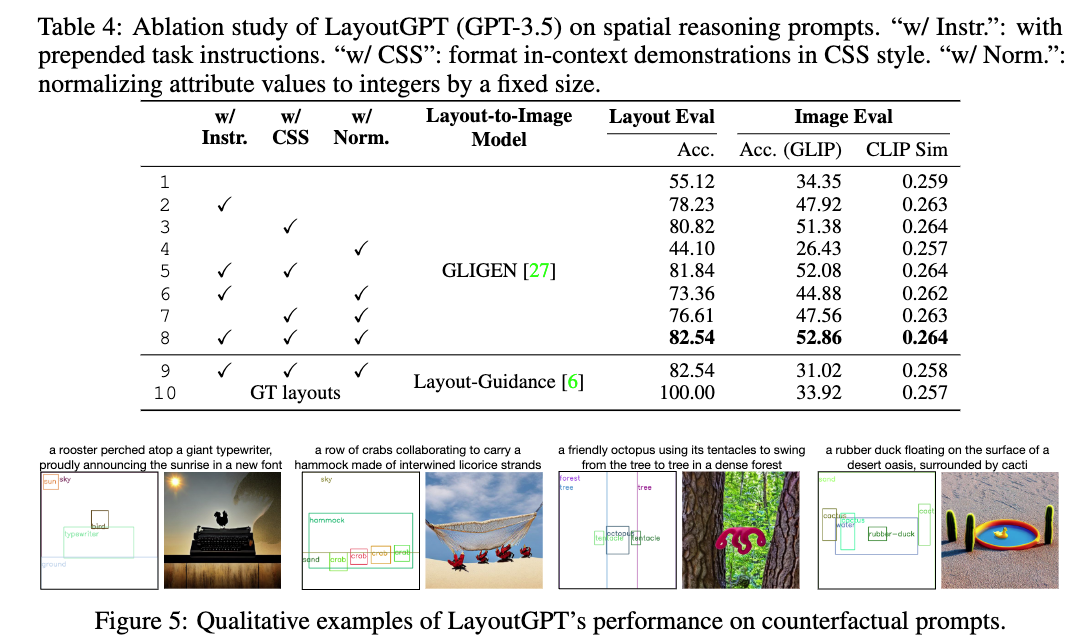
참고로 각 구성 요소들에 대한 ablation study 결과는 아래와 같습니다. Instruct를 주는지 안 주는지에 따라서 성능이 굉장히 많이 달라지는 것을 알 수 있습니다.
실내 장면 합성에 대한 결과는 아래와 같습니다. 정량적으로는 학습 없이도 supervised learning 모델과 비슷한 성능을 보였습니다. 또한 정성적으로는 ATISS에서 발생했던 가구가 겹치는 문제가 가구가 바운더리를 나가는 문제가 완회되었다고 합니다.

LayoutGPT는 혁신적인 성과를 냈지만, 여전히 개선 여지가 있습니다. 예를 들어, 객체가 중첩되거나 공간을 벗어나는 오류가 발생할 수 있으며, 이는 기존 ATISS 모델에서도 나타나는 문제입니다. 따라서 보다 정교한 플래닝과 충돌 방지 기술의 도입이 필요할 것으로 보인다고 합니다.
최종적으로 해당 논문은 당 같은 결론으로 마무리 짓고 있습니다.
“LayoutGPT는 LLM의 시각적 레이아웃 생성 가능성을 입증하며, 텍스트와 이미지를 조화롭게 결합하는 차세대 생성 모델의 가능성을 열어주고 있습니다. 텍스트와 3D 공간의 맥락을 이해하고, 이를 시각적으로 구현하는 LLM의 역할이 더욱 기대됩니다.”
개인적으로 학습 없이 LMM을 이용해서 레이아웃을 생성하고, 그 레이아웃을 css 형태로 정의한 것이 인상 깊었습니다. 레이아웃 생성 같은 경우는 학습이 없이도 동작하기 때문에 매우 실용적이라는 생각이 들었습니다.